Python Data Pipeline Automation
In today’s data-driven landscape, the ability to efficiently process and analyze vast amounts of information is no longer a luxury—it’s a necessity. Raw data, however, is often messy, inconsistent, and spread across disparate systems. This is where data pipelines come in, serving as the automated workflows that ingest, clean, and transform this raw material into actionable insights. Automating these processes is crucial for scalability, reliability, and speed. Among the many tools available, Python has emerged as the undisputed leader for building these critical systems. Its simple syntax, combined with an incredibly rich ecosystem of libraries, makes it the perfect language for data engineers and developers tasked with creating robust data processing workflows.
This comprehensive guide will take you through the entire lifecycle of Python data pipeline automation. We will start with the fundamental concepts of ETL (Extract, Transform, Load) and explore the core components of a pipeline. From there, we’ll dive into practical, hands-on examples using popular libraries like Pandas and Requests. Finally, we’ll elevate our understanding by tackling production-level concerns, including data validation, sophisticated error handling, and essential monitoring strategies. By the end, you will have a clear roadmap for building data systems that are not just functional, but also resilient, maintainable, and ready for the demands of a real-world environment.
Foundations of Python Data Pipelines
Before writing a single line of code, it’s essential to understand the conceptual framework of a data pipeline. At its core, a data pipeline is a series of interconnected processing steps. Think of it as a digital assembly line: raw materials (data) enter at one end, undergo a series of automated operations, and emerge as a finished product (structured, analysis-ready information) at the other. The primary goal is to move data from one or more sources—such as databases, APIs, or log files—to a destination, like a data warehouse or an analytics dashboard, applying necessary transformations along the way.
The Core Stages: ETL vs. ELT
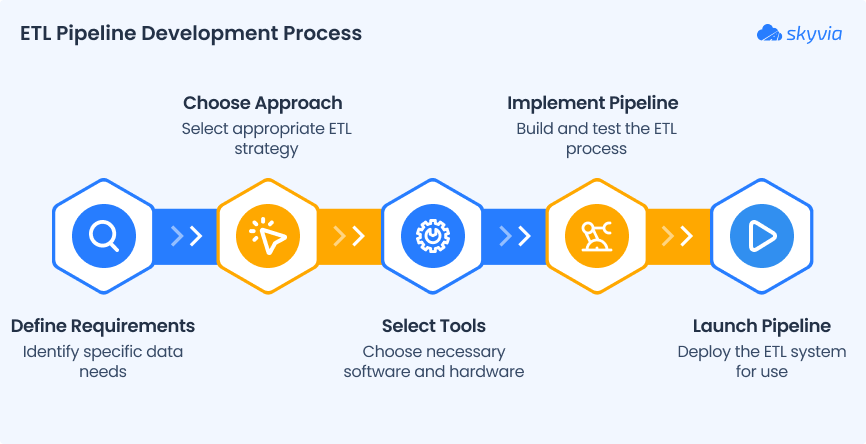
Data pipelines are most commonly described by the acronym ETL, which stands for Extract, Transform, and Load. This classic model has been the bedrock of data warehousing for decades.
- Extract: This is the first step, where data is retrieved from its original source. Python excels here with libraries for every conceivable source. You might use
psycopg2orSQLAlchemyto connect to a PostgreSQL database, therequestslibrary to pull data from a REST API, orboto3to access files in an Amazon S3 bucket. - Transform: This is the most critical stage, where the raw data is cleaned, validated, enriched, and reshaped. Transformations can range from simple tasks like renaming columns and converting data types to complex operations like joining multiple datasets, aggregating records, or running machine learning models. This is where Python’s data manipulation libraries, especially Pandas, Polars, and Dask, truly shine.
- Load: In the final step, the processed data is loaded into its target destination. This could be a relational database, a NoSQL database, a data warehouse like Google BigQuery or Snowflake, or even a simple CSV file.
A more modern alternative that has gained popularity with the rise of powerful cloud data warehouses is ELT (Extract, Load, Transform). In this paradigm, raw data is extracted and immediately loaded into the target system. The transformation logic is then executed directly within the data warehouse, leveraging its massive parallel processing power. This approach is beneficial when dealing with enormous datasets, as it avoids moving large volumes of data back and forth for transformation.
Why Python is the Ideal Choice
Python’s dominance in data engineering is no accident. It offers a unique combination of simplicity, power, and flexibility that is unmatched by other languages.
- Rich Ecosystem: Python boasts a vast collection of open-source libraries specifically designed for data work. From data wrangling (Pandas) to orchestration (Airflow, Prefect) and data validation (Great Expectations), there is a mature, well-supported tool for nearly every task.
- Simplicity and Readability: Python’s clean, intuitive syntax makes it easy to write and, more importantly, easy to maintain complex data processing logic. This lowers the barrier to entry and facilitates collaboration among team members.
- Superior Integration: Often called a “glue language,” Python seamlessly connects disparate systems. It has robust connectors for virtually every database, API, and cloud service, making it the perfect central hub for your data operations.
- Vibrant Community: The massive global community ensures that Python is constantly evolving. Whenever a new data technology emerges, you can be sure that Python connectors and libraries will follow. Staying updated with the latest
["python news"]and library releases is key to leveraging the best tools available.
The Anatomy of a Python Data Pipeline: A Practical Example
Theory is important, but the best way to understand a data pipeline is to build one. Let’s walk through a simple, practical example: we will create a pipeline that fetches user data from a public REST API, cleans and transforms it into a more usable format, and then loads it into a CSV file for analysis.
Step 1: Extraction with `requests`
Our first task is to extract data from the source. We’ll use the popular requests library to make an HTTP GET request to the JSONPlaceholder API, a free online service for testing and prototyping.
import requests
import logging
# Configure basic logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def extract_user_data(api_url: str) -> list:
"""
Extracts user data from a given API endpoint.
Args:
api_url: The URL of the API to fetch data from.
Returns:
A list of user records as dictionaries.
"""
try:
logging.info(f"Extracting data from {api_url}")
response = requests.get(api_url)
response.raise_for_status() # Raises an HTTPError for bad responses (4xx or 5xx)
logging.info("Data extraction successful.")
return response.json()
except requests.exceptions.RequestException as e:
logging.error(f"Error during data extraction: {e}")
return None
In this function, we not only fetch the data but also include basic error handling with a try...except block and use response.raise_for_status() to automatically check for bad HTTP responses. Logging is added to provide visibility into the process.
Step 2: Transformation with `pandas`
Once we have the raw JSON data, we need to transform it. The pandas library is the industry standard for this kind of in-memory data manipulation. We’ll load the data into a DataFrame and perform several cleaning operations.
import pandas as pd
def transform_data(users_json: list) -> pd.DataFrame:
"""
Transforms raw user data into a clean DataFrame.
Args:
users_json: A list of user dictionaries.
Returns:
A cleaned and structured pandas DataFrame.
"""
if not users_json:
logging.warning("No data to transform.")
return pd.DataFrame()
logging.info("Starting data transformation.")
df = pd.DataFrame(users_json)
# 1. Select and rename relevant columns
df_transformed = df[['id', 'name', 'email', 'address', 'company']].copy()
df_transformed.rename(columns={'id': 'user_id', 'name': 'full_name'}, inplace=True)
# 2. Unpack nested JSON objects into new columns
df_transformed['city'] = df_transformed['address'].apply(lambda x: x.get('city'))
df_transformed['company_name'] = df_transformed['company'].apply(lambda x: x.get('name'))
# 3. Drop original complex columns
df_transformed.drop(columns=['address', 'company'], inplace=True)
# 4. Ensure consistent data types
df_transformed['user_id'] = df_transformed['user_id'].astype(int)
logging.info("Data transformation complete.")
return df_transformed
This transformation step is a perfect example of Python’s power. In just a few lines of code, we’ve selected columns, renamed them for clarity, flattened nested JSON structures into top-level columns, and ensured data type consistency.
Step 3: Loading the Data
The final step is to load our transformed data into its destination. For this example, we’ll save it as a CSV file, a common format for simple data storage and sharing.
def load_data(df: pd.DataFrame, output_path: str):
"""
Loads a DataFrame into a CSV file.
Args:
df: The DataFrame to load.
output_path: The file path for the output CSV.
"""
if df.empty:
logging.warning("DataFrame is empty. Skipping load process.")
return
try:
logging.info(f"Loading data to {output_path}")
df.to_csv(output_path, index=False)
logging.info("Data loading successful.")
except IOError as e:
logging.error(f"Error loading data to file: {e}")
From Script to System: Making Your Pipeline Robust
Having a script that runs an ETL process is a great start, but a production-grade data pipeline requires more. It must be reliable, resilient to failure, and observable. This involves adding layers of data validation, error handling, and monitoring.
Data Validation: Trusting Your Data
The principle of “garbage in, garbage out” is critically important in data engineering. If you ingest low-quality data, your analyses and business decisions will be flawed. Data validation is the process of enforcing rules and constraints on your data to ensure its quality and integrity. Libraries like Pandera and Great Expectations are designed for this.
With Pandera, you can define a schema that your DataFrame must adhere to. This schema can check data types, value ranges, uniqueness, and more.
import pandera as pa
from pandera.typing import Series
class UserSchema(pa.SchemaModel):
user_id: Series[int] = pa.Field(unique=True, gt=0)
full_name: Series[str]
email: Series[str] = pa.Field(str_contains='@')
city: Series[str] = pa.Field(nullable=True)
company_name: Series[str]
# You would integrate this into your transform function:
def validate_and_transform(users_json: list) -> pd.DataFrame:
df = transform_data(users_json) # Perform initial transformation
if not df.empty:
try:
UserSchema.validate(df, lazy=True)
logging.info("Data validation successful.")
except pa.errors.SchemaErrors as err:
logging.error("Data validation failed!")
logging.error(err.failure_cases)
# Decide how to handle bad data: quarantine it, drop it, or fail the pipeline
return pd.DataFrame() # Return empty frame on failure
return df
Robust Error Handling and Logging
Failures are inevitable in distributed systems. APIs can go down, databases can become unresponsive, and data formats can change unexpectedly. A robust pipeline anticipates these failures and handles them gracefully.
- Retries with Exponential Backoff: For transient network errors, simply retrying the operation after a short delay is often effective. Libraries like
tenacitycan be used to easily add retry logic to any function (e.g., your `extract_user_data` function). - Structured Logging: Go beyond simple print statements. Use Python’s built-in
loggingmodule to create structured logs that include timestamps, severity levels (INFO, WARNING, ERROR), and contextual information. These logs are invaluable for debugging failed pipeline runs. - Alerting: For critical failures, logging is not enough. Your system should actively notify you. Integrate your pipeline with alerting tools like Sentry, PagerDuty, or even a simple Slack webhook to send notifications when a pipeline run fails.
Monitoring and Observability
You need to know how your pipeline is performing over time. Monitoring provides this visibility. Key metrics to track include:
- Pipeline Health: Track run duration, success/failure rates, and the timestamp of the last successful run.
- Data Volume: Monitor the number of records processed in each run. A sudden drop or spike can indicate an upstream problem.
- Data Quality: Log the number of records that fail validation. An increase in validation failures could signal a change in a source API.
Orchestration tools often provide dashboards for this, but you can also integrate with dedicated monitoring systems like Prometheus and Grafana for more advanced observability.
Orchestrating and Scaling Your Pipelines
A single script is run manually. A true automated pipeline is managed by an orchestrator. An orchestration framework is responsible for scheduling your pipeline runs, managing dependencies between tasks, handling retries, and providing a user interface for monitoring and management.
Choosing an Orchestration Framework
Several excellent Python-based orchestration tools are available, each with different strengths:
- Apache Airflow: The long-standing industry standard. It is incredibly powerful and extensible but can have a steeper learning curve. It’s best suited for complex, enterprise-scale workflows with many interdependencies.
- Prefect: Designed as a modern, developer-friendly alternative to Airflow. It offers a more Pythonic “code-as-workflows” approach that is often easier for developers to adopt and debug.
- Dagster: A data-aware orchestrator that focuses on the data assets produced by your pipeline. It provides excellent tools for data lineage, cataloging, and observability, making it a strong choice for teams that prioritize data quality.
- Cron: For very simple, standalone tasks, a classic cron job on a Linux server can be sufficient. However, it lacks the advanced features of a true orchestrator, such as dependency management, a UI, and built-in retry logic.
Best Practices for Maintainable Pipelines
As your data systems grow, maintainability becomes paramount. Follow these best practices to ensure your pipelines remain robust and easy to manage.
- Idempotency: An idempotent task is one that can be run multiple times with the same input and produce the same result. This is crucial for safely retrying failed tasks without creating duplicate data or other side effects.
- Modularity: Break your pipeline into small, single-purpose, and independently testable tasks (e.g., `extract`, `transform`, `validate`, `load`). This makes the code easier to understand, debug, and reuse.
- Configuration Management: Never hardcode credentials, file paths, or API endpoints in your code. Store them in a separate configuration file (e.g., YAML) or use environment variables. This makes it easy to promote your pipeline between development, staging, and production environments.
- Testing: Write unit tests for your transformation logic to verify its correctness. In addition, create integration tests that run the entire pipeline with sample data to ensure all components work together as expected.
Conclusion
Automating data pipelines with Python is a powerful way to transform raw data into a strategic asset. We have journeyed from the fundamental concepts of ETL to building a practical pipeline with `requests` and `pandas`, and finally to fortifying it with production-grade features like data validation, robust error handling, and orchestration. Python’s versatility, combined with its world-class libraries and supportive community, provides all the tools necessary to build sophisticated and reliable data systems.
The key takeaway is that a successful data pipeline is more than just a script; it is a well-architected system. By embracing best practices such as modularity, idempotency, and comprehensive testing, and by leveraging powerful orchestration tools, you can build automated workflows that are scalable, maintainable, and resilient. As the data landscape continues to evolve, staying current with the latest tools and techniques discussed in ["python news"] and community forums will empower you to tackle any data challenge and deliver consistent value to your organization.


