
















Donot Miss


Highlight
Popular News
Django Async ORM Migration: What Breaks and When to Stay Sync Migration cost The boundary…
Django Async ORM Migration: What Breaks and When to Stay Sync
Django Async ORM Migration: What Breaks and When to Stay Sync Migration cost The boundary charges twice.
The Case for MicroPython Over C on Edge AI Devices
At first glance, C looks like the responsible choice for edge AI, but duty-cycled deployment changes the bill.
How Ibis Lowers One Expression to Three SQL Dialects
Understand ibis deferred expression backends, the main trade-offs, and the practical checks to use before relying on it in practice.
How MicroPython’s Garbage Collector Survives on 256KB
A forum question that comes back every few months goes like this: “Why does gc.collect() take about the same time on my Pico whether the heap is almost.
Inside Pydantic v2’s Core: How pydantic-core Compiles Schemas to
Understand pydantic core schema compilation, the main trade-offs, and the practical checks to use before relying on it in practice.
Inside Hypothesis’s Shrinker: How Pareto Minimization Finds Smaller Failing Examples
By Riko Ishikawa When Hypothesis catches a property violation, the failing input you eventually see in the traceback is almost never the input the.

Inside Polars’ Streaming Engine: How Spillable Sinks Handle Larger-Than-RAM Joins
If you search polars streaming engine spill today, the top result is a benchmark that OOM’d on Polars 1.6.0 in September 2024.
Inside Polars’ Lazy Query Engine: How Predicate Pushdown Beats Pandas
The pola.rs blog has a headline number that every Polars tutorial copies: the optimized lazy plan runs roughly 4x faster than the naive one on the NYC.
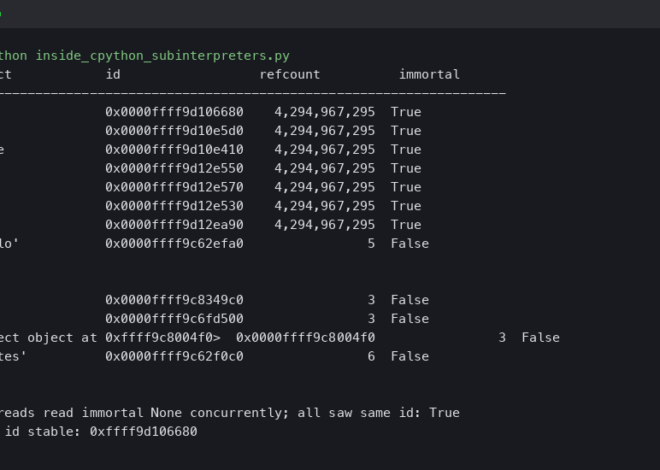
Inside CPython Sub-Interpreters: How Immortal Objects Share Memory Without the GIL
The technical barrier that kept Python’s sub-interpreter feature from being genuinely useful for a decade wasn’t parallelism — it was reference counting.
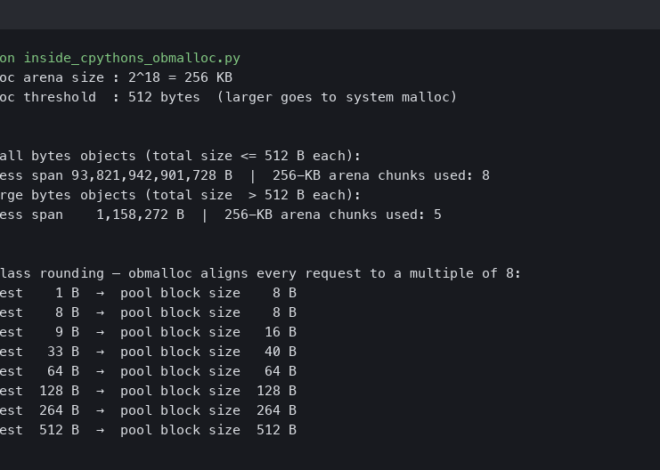
Inside CPython’s obmalloc: How the Small Object Allocator Avoids the System Heap
Jump to: What exactly does obmalloc manage, and what falls through to system malloc? · How are arenas, pools, and blocks structured inside CPython?