Django REST Framework Best Practices – Part 5
Welcome to the fifth installment of our comprehensive series on mastering Django REST Framework. In the previous parts, we laid the groundwork for building robust APIs. Now, we venture into a critical domain that separates good APIs from great ones: performance, scalability, and advanced optimization. In the fast-paced world of Python news and web development, performance is not a feature; it’s a necessity. An API that is slow, unresponsive, or unable to handle load will quickly be abandoned by users and developers alike.
This guide will equip you with the essential best practices for building scalable, maintainable, and lightning-fast REST APIs. We will move beyond the basics of serialization and authentication to explore the nuanced art of database query optimization, intelligent caching strategies, and offloading long-running tasks. These advanced techniques are crucial for applications that need to serve thousands of concurrent users, process large datasets, and provide a seamless user experience. By the end of this article, you will have a practical toolkit to diagnose bottlenecks, implement effective solutions, and architect your Django REST Framework projects for future growth.
The Foundation of Performance: Mastering Database Interactions
The most common performance bottleneck in any web application, including those built with DRF, is the database. Inefficient queries can bring even the most powerful servers to their knees. Optimizing how your API interacts with the database is the single most impactful step you can take to improve response times and scalability. Let’s explore the most critical techniques.
Tackling the N+1 Query Problem with `select_related` and `prefetch_related`
The “N+1 query problem” is an infamous performance anti-pattern. It occurs when your code executes one query to fetch a list of objects and then executes N additional queries inside a loop to fetch related data for each of those objects. This is especially common with nested serializers in DRF.
Imagine you have models for `Author` and `Book`, where each book has a foreign key to its author.
# models.py
class Author(models.Model):
name = models.CharField(max_length=100)
class Book(models.Model):
title = models.CharField(max_length=200)
author = models.ForeignKey(Author, related_name='books', on_delete=models.CASCADE)
Now, consider a simple view to list all books and their author’s name. A naive implementation might look like this:
# serializers.py
class AuthorSerializer(serializers.ModelSerializer):
class Meta:
model = Author
fields = ['name']
class BookSerializer(serializers.ModelSerializer):
author = AuthorSerializer() # Nested serializer
class Meta:
model = Book
fields = ['id', 'title', 'author']
# views.py
class BookListView(generics.ListAPIView):
queryset = Book.objects.all() # The source of the problem!
serializer_class = BookSerializer
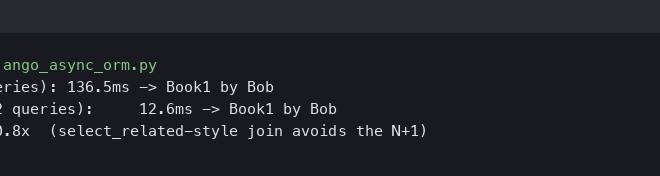
If you have 100 books, this view will execute 101 database queries: 1 to get all books, and then 100 more (one for each book) to get the author’s details. This is incredibly inefficient.
The Solution:

select_related: Use this for `ForeignKey` and `OneToOneField` relationships. It performs a SQL JOIN in the initial query, fetching the related objects in a single, more complex query.prefetch_related: Use this for `ManyToManyField` and reverse `ForeignKey` relationships. It works by performing a separate lookup for the related objects and then “joining” them in Python. This avoids the massive JOINs that can be inefficient for many-to-many relations.
Here’s the optimized view:
# views.py (Optimized)
class BookListView(generics.ListAPIView):
# Use select_related for the ForeignKey relationship
queryset = Book.objects.select_related('author').all()
serializer_class = BookSerializer
With this one change, Django will now execute only one database query. The performance gain is immense, and this approach is a hot topic in many Python development circles because of its immediate impact.
Reducing Payload with `only()` and `defer()`
Sometimes, you don’t need all the data from a model. Fetching large text fields or binary data when you only need an ID and a title is wasteful. Django’s QuerySet API provides `only()` and `defer()` to control which fields are retrieved from the database.
only(*fields): Specifies that only the given fields should be loaded from the database.defer(*fields): Specifies that all fields *except* the given ones should be loaded.
For example, if you have a `BlogPost` model with a large `content` field but your list view only shows the `title` and `publication_date`, you can optimize it like this:
# views.py
class BlogPostListView(generics.ListAPIView):
# Defer loading the large 'content' field
queryset = BlogPost.objects.defer('content').all()
serializer_class = BlogPostListSerializer
Leveraging Caching for Instantaneous Responses
After optimizing your database queries, the next layer of performance enhancement is caching. Caching involves storing the result of an expensive operation (like a database query or a rendered API response) and serving the stored result for subsequent, identical requests. Django has a robust caching framework that integrates seamlessly with DRF.
View-Level Caching with Decorators
The simplest way to implement caching is at the view level. This is perfect for endpoints where the data doesn’t change frequently, such as a list of product categories or public user profiles.
First, configure your cache backend in `settings.py`. For production, Redis or Memcached are excellent choices.
# settings.py
CACHES = {
'default': {
'BACKEND': 'django_redis.cache.RedisCache',
'LOCATION': 'redis://127.0.0.1:6379/1',
'OPTIONS': {
'CLIENT_CLASS': 'django_redis.client.DefaultClient',
}
}
}
Then, you can use the `@cache_page` decorator on your views. This decorator caches the entire output of the view for a specified duration.
# views.py
from django.utils.decorators import method_decorator
from django.views.decorators.cache import cache_page
class ProductCategoryListView(generics.ListAPIView):
queryset = ProductCategory.objects.all()
serializer_class = ProductCategorySerializer
# Cache this view for 15 minutes (900 seconds)
@method_decorator(cache_page(60 * 15))
def get(self, *args, **kwargs):
return super().get(*args, **kwargs)
Now, the first request to this endpoint will hit the database and render the response. That response will be stored in Redis. Subsequent requests within the next 15 minutes will be served directly from the cache, bypassing the database and serializers entirely, resulting in near-instant response times.
Granular Caching with the Low-Level Cache API
Sometimes, caching an entire view is too coarse. You might need to cache just a specific, computationally expensive part of your logic. For this, Django’s low-level cache API is perfect.
Imagine a dashboard endpoint that aggregates complex sales data. This aggregation might be slow. You can cache just the result of this aggregation.
# views.py
from django.core.cache import cache
class SalesDashboardAPIView(APIView):
def get(self, request, *args, **kwargs):
# Define a unique cache key
cache_key = 'sales_dashboard_data'
# Try to get the data from the cache
data = cache.get(cache_key)
if data is None:
# Data not in cache, so we compute it
data = self.calculate_complex_sales_metrics()
# Store the result in the cache for 1 hour
cache.set(cache_key, data, timeout=3600)
return Response(data)
def calculate_complex_sales_metrics(self):
# ... your slow, database-intensive logic here ...
return {"total_sales": 100000, "top_product": "Widget A"}
Offloading Heavy Lifting with Asynchronous Tasks
Not all tasks should be handled within the request-response cycle. Operations that are slow or resource-intensive, such as sending emails, processing uploaded images, generating reports, or calling third-party APIs, can block the server and lead to request timeouts. The best practice is to offload these tasks to a background worker process.
Integrating Celery for Background Processing
Celery is the de-facto standard for task queues in the Python ecosystem. It allows you to define tasks that can be executed asynchronously by separate worker processes.
Consider an API endpoint for user registration. After a user signs up, you want to send them a welcome email. Doing this synchronously can add a noticeable delay to the API response.
Step 1: Define a Celery Task
# your_app/tasks.py
from celery import shared_task
from django.core.mail import send_mail
@shared_task
def send_welcome_email_task(user_id):
# Logic to fetch user and send email
from django.contrib.auth.models import User
try:
user = User.objects.get(pk=user_id)
send_mail(
'Welcome to Our Platform!',
f'Hi {user.username}, thank you for registering.',
'[email protected]',
[user.email],
fail_silently=False,
)
except User.DoesNotExist:
# Handle case where user might have been deleted
pass
Step 2: Call the Task from Your View
In your DRF view, instead of calling the email sending logic directly, you trigger the Celery task. The latest news in the Python ecosystem often highlights the growing importance of asynchronous programming, and this is a prime example.
# views.py
class UserRegistrationView(generics.CreateAPIView):
queryset = User.objects.all()
serializer_class = UserRegistrationSerializer
def perform_create(self, serializer):
user = serializer.save()
# Offload the email sending to a background worker
send_welcome_email_task.delay(user.id)
The `delay()` method immediately returns, adding the task to the queue (e.g., RabbitMQ or Redis). Your API can then instantly return a `201 Created` response to the user. The Celery worker will pick up the task and execute it in the background, ensuring the user experience is fast and snappy.
Additional Performance Considerations
Smart Pagination
Never return an unbounded list of results from an API endpoint. If your `Product` table has 1 million rows, an unpaginated `/api/products/` endpoint would try to serialize all 1 million objects, likely crashing your server. Always use pagination. DRF provides several styles, with `LimitOffsetPagination` and `CursorPagination` being excellent choices for performance and stability.
Profiling Your API
You can’t optimize what you can’t measure. Tools like `django-debug-toolbar` are invaluable during development for inspecting the number of queries, cache hits/misses, and time spent in different parts of the request. For production profiling, tools like `py-spy` or New Relic can help you identify real-world performance bottlenecks.
Choose the Right Renderer
While `JSONRenderer` is the default and usually the right choice, be aware of its performance characteristics. For extremely high-performance needs where every microsecond counts, you might consider alternative renderers like `UJSONRenderer` or even binary formats like MessagePack if the client supports it.
Conclusion
Building high-performance, scalable APIs with Django REST Framework is an achievable goal that hinges on a few core principles. By diligently optimizing your database interactions, implementing a multi-layered caching strategy, and intelligently offloading long-running tasks, you can ensure your application remains fast and responsive as it grows. Remember to start with the database—tackling N+1 query problems is often the biggest win. Then, layer on caching for frequently accessed, static data. Finally, use asynchronous workers to keep your request-response cycle lean and quick.
By incorporating these advanced best practices into your development workflow, you will not only improve the end-user experience but also build a more robust, maintainable, and scalable backend architecture ready to meet the demands of a modern web application.