
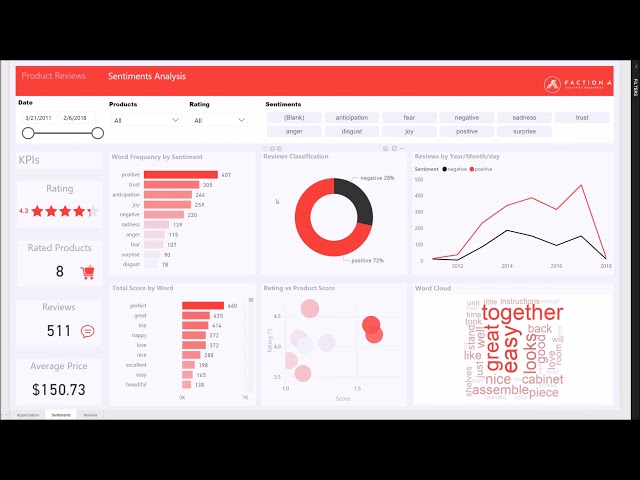
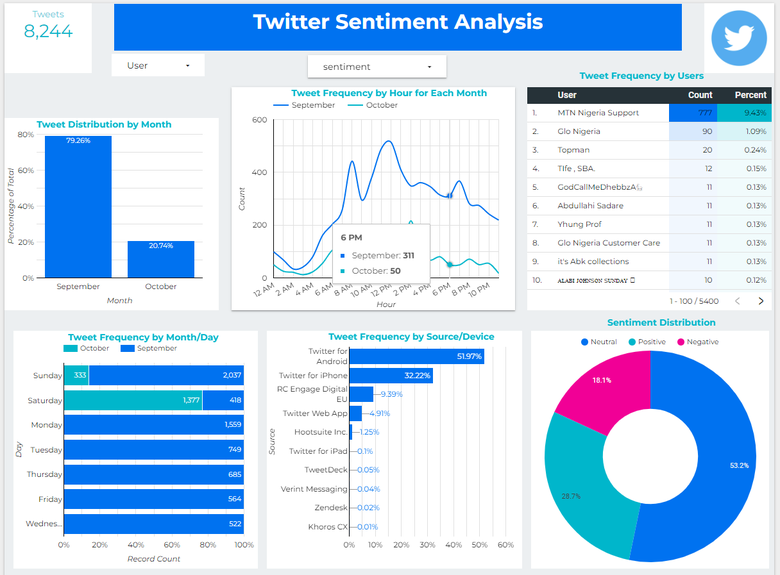
Building an AI-Powered Public Opinion Analyzer with Python: A Deep Dive into Social Media News Extraction
In today’s hyper-connected world, social media platforms have become the de facto public square, a ceaseless torrent of opinions, reactions, and breaking news. For developers, data scientists, and businesses, this stream of data is a goldmine of insights. However, manually sifting through millions of posts is an impossible task. This is where Python, with its rich ecosystem of AI and machine learning libraries, truly shines. The latest trend in python news and development is the rise of sophisticated tools designed to analyze public opinion, extract meaningful news, and gauge sentiment in real-time.
These AI-driven systems are not just about counting likes or retweets; they delve into the nuances of human language to understand context, emotion, and key topics of discussion. By building such a tool, one can track brand perception, understand public reaction to policy changes, or even detect emerging social trends. This article provides a comprehensive technical guide to building your own public opinion analyzer. We will explore the architecture, dive into practical Python code for each component—from data ingestion to sentiment analysis—and discuss the real-world applications and ethical considerations that are paramount in this domain.
The Core Architecture of an AI Opinion Analyzer
Before writing a single line of code, it’s crucial to understand the conceptual framework of a system designed to analyze public opinion. A robust analyzer can be broken down into four distinct, interconnected layers. Each layer handles a specific part of the process, transforming raw, unstructured social media text into structured, actionable intelligence.
1. Data Ingestion and Acquisition
This is the entry point of our system. Its sole purpose is to collect raw data from various sources. In the context of social media, this typically involves interacting with APIs from platforms like X (formerly Twitter), Reddit, or news aggregators. Key challenges here include handling API rate limits, managing authentication keys securely, and designing a resilient data pipeline that can cope with connection interruptions or changes in the API’s data format. The output of this layer is a stream of raw data, often in JSON format, containing text, metadata (timestamps, user info), and other relevant details.
2. The NLP Core: Extraction and Structuring
Once we have the raw text, the Natural Language Processing (NLP) core gets to work. This is the brain of the operation, where unstructured text is converted into structured information. A primary task here is Named Entity Recognition (NER), which identifies and categorizes key entities within the text, such as names of people, organizations, locations, products, and events. For example, in the post “Just read that QuantumLeap Inc. is launching their new ‘Photon’ smartphone in San Francisco next week!”, the NLP core would extract “QuantumLeap Inc.” (Organization), “Photon” (Product), and “San Francisco” (Location). This process is fundamental for understanding what people are talking about.
3. The Sentiment Analysis Engine
Knowing what people are discussing is only half the story; we also need to understand how they feel about it. The Sentiment Analysis Engine analyzes the emotional tone of the text. It classifies a piece of text as positive, negative, or neutral. More advanced models can even detect nuanced emotions like joy, anger, or surprise. This layer often uses pre-trained models that understand the subtleties of language, including slang, emojis, and sarcasm, which are prevalent on social media. The output is typically a set of scores—for example, a polarity score ranging from -1 (very negative) to +1 (very positive) and a subjectivity score indicating if the text is factual or opinion-based.
4. Data Storage and Management
Finally, the structured data and its associated sentiment scores need to be stored for analysis and retrieval. This layer involves designing a database schema to hold the processed information. Options range from simple CSV files for small-scale projects to more robust solutions like SQLite, PostgreSQL, or NoSQL databases like MongoDB for larger applications. An effective storage system allows for efficient querying, such as “Show me all negative comments about ‘Product X’ from the last 24 hours” or “Track the sentiment trend for ‘Company Y’ over the past month.”
Keywords:
Social media data analytics dashboard – Comparison of Social Media Monitoring Tools (Continued) | Download …
Practical Implementation: From Raw Text to Actionable Insights
Let’s translate the architecture into a practical Python implementation. We’ll build a simplified pipeline that processes a sample of social media data, extracts entities, and analyzes sentiment. This will serve as the foundation for a more complex system.
Setting Up the Environment
First, you’ll need to install the necessary libraries. We’ll use spaCy for advanced NLP and NER, and vaderSentiment, a library specifically tuned for social media text.
pip install spacy vaderSentiment
python -m spacy download en_core_web_sm
The `OpinionProcessor` Class
We’ll encapsulate our logic within a class to keep the code organized and reusable. This class will handle the entire processing pipeline for a single piece of text.
import spacy
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
from dataclasses import dataclass, asdict
from typing import List, Dict, Any
# A data class to hold our structured results
@dataclass
class ProcessedPost:
text: str
sentiment: Dict[str, float]
entities: List[Dict[str, str]]
keywords: List[str]
class OpinionProcessor:
“””
A class to process social media text for news extraction and sentiment analysis.
“””
def __init__(self):
# Load the small English model for spaCy
self.nlp = spacy.load(“en_core_web_sm”)
# Initialize the VADER sentiment analyzer
self.analyzer = SentimentIntensityAnalyzer()
print(“OpinionProcessor initialized.”)
def analyze_sentiment(self, text: str) -> Dict[str, float]:
“””Analyzes the sentiment of a given text using VADER.”””
return self.analyzer.polarity_scores(text)
def extract_entities(self, text: str) -> List[Dict[str, str]]:
“””Extracts named entities from text using spaCy.”””
doc = self.nlp(text)
entities = [
{“text”: ent.text, “label”: ent.label_}
for ent in doc.ents
]
return entities
def extract_keywords(self, text: str) -> List[str]:
“””Extracts meaningful keywords (nouns and proper nouns).”””
doc = self.nlp(text)
keywords = [
token.lemma_.lower()
for token in doc
if not token.is_stop and not token.is_punct and token.pos_ in [“NOUN”, “PROPN”]
]
return list(set(keywords)) # Return unique keywords
def process(self, text: str) -> ProcessedPost:
“””Runs the full analysis pipeline on a single piece of text.”””
sentiment = self.analyze_sentiment(text)
entities = self.extract_entities(text)
keywords = self.extract_keywords(text)
return ProcessedPost(
text=text,
sentiment=sentiment,
entities=entities,
keywords=keywords
)
# — Example Usage —
if __name__ == ‘__main__’:
# Simulate a stream of social media posts
posts = [
“QuantumLeap Inc. just announced their new Photon phone in San Francisco! It looks amazing, I’m so excited! 😍”,
“The Photon phone by QuantumLeap is a huge disappointment. The battery life is terrible. Avoid at all costs.”,
“Just saw the latest python news: the new version of the framework is 2x faster. Great work by the core team at Python Foundation.”,
“Stock for QuantumLeap Inc. (QLI) is down 5% after the mixed reviews of the Photon.”
]
processor = OpinionProcessor()
processed_results = []
for post in posts:
result = processor.process(post)
processed_results.append(asdict(result))
# Print the results in a readable format
import json
print(json.dumps(processed_results, indent=2))
Breaking Down the Code
The code above demonstrates our pipeline in action. The OpinionProcessor class initializes both spaCy and VADER. The process method orchestrates the analysis:
Sentiment Analysis: analyze_sentiment uses VADER, which returns a dictionary with negative, neutral, positive, and a compound score. The compound score is a normalized, weighted composite that is very useful for overall sentiment assessment (-1 is most negative, +1 is most positive).
Entity Extraction: extract_entities uses spaCy’s pre-trained model to identify entities like “QuantumLeap Inc.” (ORG), “San Francisco” (GPE – Geopolitical Entity), and “5%” (PERCENT).
Keyword Extraction: To get a better sense of the core topics, extract_keywords pulls out important nouns and proper nouns, filtering out common “stop words” like “the,” “is,” and “a.”
Structured Output: The ProcessedPost data class provides a clean, predictable structure for our results, which can then be easily converted to JSON or inserted into a database.
Implications, Insights, and Ethical Considerations
A tool like this has far-reaching implications. It can democratize market research, provide journalists with real-time public pulse data, and help organizations manage their public relations proactively. The latest python news often revolves around making these powerful AI capabilities more accessible, and tools like this are a prime example.
Case Study: Tracking a Product Launch
Imagine a company, “QuantumLeap Inc.,” launching a new smartphone. Using our `OpinionProcessor`, they could analyze thousands of posts in real-time. By aggregating the results, they could:
Gauge Initial Reception: Is the overall sentiment positive or negative? The average compound score from VADER would provide an immediate answer.
Identify Key Issues: By analyzing keywords in negative posts (e.g., “battery,” “screen,” “price”), the company can quickly pinpoint specific problems that users are complaining about.
Track Competitor Mentions: The entity recognition can identify when users compare their product to competitors, providing valuable competitive intelligence.
Measure Geographic Reach: By extracting location entities, they can see where the conversation is most active, helping to target marketing efforts.
The Ethical Tightrope: Bias, Privacy, and Misinformation
Python code on computer screen – It business python code computer screen mobile application design …
With great power comes great responsibility. Building and deploying such a system requires careful ethical consideration.
Algorithmic Bias: Pre-trained models can inherit biases from the data they were trained on. A model might incorrectly associate certain dialects or demographic language with negative sentiment. It’s crucial to be aware of these limitations and, where possible, fine-tune models on domain-specific, unbiased data.
User Privacy: While analyzing public data, it’s essential to respect user privacy. The focus should be on aggregated trends, not individual users. Anonymizing data and avoiding the storage of personally identifiable information (PII) is a critical best practice.
Manipulation and Misinformation: These tools can be used to identify and track misinformation campaigns, but they could also be used to create them. Developers have a responsibility to consider the potential for misuse of their technology.
Best Practices and Recommendations
To move from a simple script to a production-ready system, consider the following best practices.
1. Choose the Right Tool for the Job
While we used VADER and spaCy, the Python ecosystem offers many alternatives.
TextBlob: A simpler library for sentiment analysis. It’s great for beginners but less nuanced than VADER for social media.
Hugging Face Transformers: For state-of-the-art accuracy, libraries like transformers provide access to large language models (LLMs) like BERT or RoBERTa. These models offer superior performance but require more computational resources.
NLTK (Natural Language Toolkit): A foundational library that is excellent for academic use and learning NLP concepts from the ground up, though it can be more verbose for production tasks compared to spaCy.
Recommendation: Start with VADER for sentiment and spaCy for general NLP. If accuracy becomes a bottleneck, explore fine-tuning a model from the Hugging Face ecosystem.
2. Preprocessing is Key
Social media text is messy. Before analysis, you should always perform a preprocessing step to clean the data. This includes:
Python code on computer screen – The 6 Best Jobs You Can Get If You Know Python
Converting text to lowercase.
Removing URLs, mentions (@username), and hashtags (#topic).
Expanding contractions (e.g., “don’t” to “do not”).
Handling emojis, which can carry significant sentiment.
3. Manage API Usage Gracefully
When collecting data from live APIs, you will inevitably hit rate limits. Your data ingestion script should be designed to handle this. Implement exponential backoff—a strategy where you wait for progressively longer periods after each failed request—to avoid being blocked by the service.
4. Scale Your Data Storage
For a small project, printing to the console or saving to a CSV is fine. For a real application, you need a database. SQLite is an excellent, serverless option built into Python that’s perfect for moderate amounts of data. For larger-scale applications that require concurrent access, a dedicated database server like PostgreSQL is the industry standard.
Conclusion: The Future of AI-Driven News Analysis
We’ve journeyed from the high-level architecture of a public opinion analyzer to a practical, hands-on Python implementation. By leveraging powerful libraries like spaCy and VADER, we can transform the chaotic noise of social media into a structured and insightful source of python news and public sentiment. The key takeaway is that Python provides a complete, end-to-end toolkit for this complex task, empowering developers to build sophisticated AI applications with remarkable efficiency.
However, the technical implementation is only one part of the equation. As developers and data scientists, we must remain vigilant about the ethical implications of our work, ensuring that these powerful tools are used to foster understanding and positive change, rather than to exploit or manipulate. The ability to analyze public opinion at scale is a transformative capability, and with a responsible approach, it can offer unprecedented insights into the dynamics of our society.


