
Python Microservices Architecture Guide – Part 4
Welcome back to our comprehensive series on building robust microservices architecture using Python. In the previous installments, we laid the groundwork, exploring the fundamental concepts, designing our first services, and setting up basic infrastructure. Now, in Part 4, we venture into the deep end. We will tackle the complex, real-world challenges that separate a simple prototype from a resilient, scalable, and production-ready distributed system. This is where the true power and complexity of microservices come to light.
Building a distributed system is not merely about breaking a monolith into smaller pieces. It’s about orchestrating a symphony of independent services that must communicate effectively, maintain data integrity, be observable when things go wrong, and be deployed seamlessly. In this guide, we will dissect four critical pillars of advanced microservices architecture: sophisticated service communication, strategies for maintaining data consistency, comprehensive monitoring and observability, and modern deployment and orchestration techniques. We’ll explore practical Python implementations, discuss trade-offs, and provide actionable insights to help you navigate these advanced topics with confidence. Let’s dive in.
Mastering Service Communication: The Lifeline of Your Architecture
In a microservices ecosystem, services are useless in isolation. Their value is derived from their ability to collaborate. The way they communicate is a foundational architectural decision with profound implications for performance, resilience, and coupling. The choice boils down to two primary paradigms: synchronous and asynchronous communication.
Synchronous Communication: The Direct Approach
Synchronous communication is like a phone call—the caller makes a request and waits for an immediate response. This pattern is intuitive and often simpler to implement for request/response workflows.
RESTful APIs (HTTP/S): This is the most common approach, leveraging the ubiquity of HTTP. Python frameworks like Flask, Django REST Framework, and especially FastAPI make building high-performance REST APIs incredibly straightforward.
- Pros: Simple, stateless, human-readable, and supported by a vast ecosystem of tools (browsers, cURL, etc.).
- Cons: Can lead to tight coupling (the client is tied to the service’s availability) and can suffer from cascading failures if a downstream service becomes slow or unresponsive.
gRPC (Google Remote Procedure Call): A modern, high-performance framework that uses HTTP/2 for transport and Protocol Buffers as the interface definition language. It’s an excellent choice for internal, service-to-service communication where performance is critical.
- Pros: Extremely fast due to binary serialization, supports streaming (client-side, server-side, and bidirectional), and enforces a strict API contract through
.protofiles. - Cons: Less human-readable than JSON/REST, and has less browser support out-of-the-box.
Python gRPC Example
First, define your service contract in a .proto file:
// user.proto
syntax = "proto3";
package user;
service UserService {
rpc GetUser(UserRequest) returns (UserResponse);
}
message UserRequest {
int32 user_id = 1;
}
message UserResponse {
int32 user_id = 1;
string username = 2;
string email = 3;
}You would then use the gRPC tools to generate Python server and client stubs, which provide a strongly-typed way to implement your service logic and call it remotely.
Asynchronous Communication: Decoupling for Resilience
Asynchronous communication is like sending an email—the sender dispatches a message and doesn’t wait for an immediate reply. This is achieved using a message broker, which decouples the producer from the consumer. This pattern is the cornerstone of building resilient and scalable event-driven architectures.
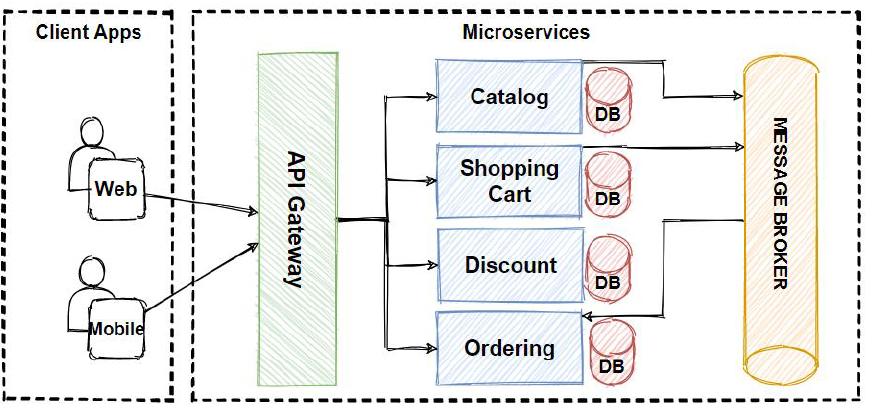
Message Queues (RabbitMQ): RabbitMQ is a mature and robust message broker that implements the Advanced Message Queuing Protocol (AMQP). It’s ideal for background jobs, task queues, and reliable messaging between services.
- Use Case: An “Order Service” publishes an
OrderCreatedevent to a RabbitMQ exchange. A “Notification Service” and an “Inventory Service” subscribe to this event to send an email and update stock levels, respectively. The Order Service doesn’t need to know or wait for them.
Python RabbitMQ Example (using pika)
# producer.py
import pika
import json
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='order_queue')
message = {'order_id': 123, 'user_id': 456, 'amount': 99.99}
channel.basic_publish(exchange='',
routing_key='order_queue',
body=json.dumps(message))
print(" [x] Sent order message")
connection.close()
# consumer.py
import pika
import json
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='order_queue')
def callback(ch, method, properties, body):
order_data = json.loads(body)
print(f" [x] Received order {order_data['order_id']}. Processing payment...")
# Add payment processing logic here
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(queue='order_queue', on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
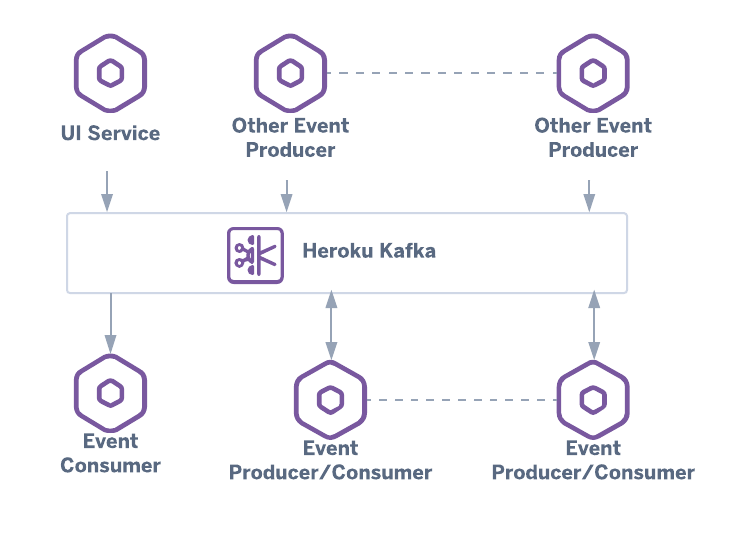
Event Streams (Apache Kafka): Kafka is a distributed streaming platform designed for high-throughput, fault-tolerant, and real-time data feeds. It’s not just a message queue but a durable log of events, allowing multiple consumers to read the stream at their own pace.
- Use Case: Aggregating logs from all microservices, tracking user activity for real-time analytics, or feeding data into a machine learning pipeline.
Ensuring Data Consistency in a Distributed System
When you move from a monolith with a single ACID-compliant database to microservices, each with its own database, you lose the ability to perform atomic transactions across services. Ensuring data consistency becomes a major architectural challenge. Staying current with **python news** and database connector updates is vital for implementing these patterns correctly.
The Saga Pattern: A Coordinated Sequence of Local Transactions
The Saga pattern is a design pattern for managing data consistency across microservices in the absence of distributed transactions. A saga is a sequence of local transactions. Each local transaction updates the database within a single service and publishes a message or event to trigger the next local transaction in the next service.
If a local transaction fails, the saga must execute a series of compensating transactions to undo the preceding transactions. For example, if “Update Inventory” fails in an order process, compensating transactions would “Cancel Payment” and “Cancel Order”.
There are two common ways to coordinate a saga:
- Choreography: A decentralized approach where each service publishes events that trigger actions in other services. It’s simple for sagas with few participants but can become complex to track and debug as the number of services grows.
- Orchestration: A centralized approach where a dedicated “Orchestrator” service is responsible for telling each participant what to do and when. It’s easier to manage complex workflows and implement compensation logic, but the orchestrator can become a single point of failure if not made highly available.
Eventual Consistency: Embracing the Reality
In most distributed systems, you must trade strong consistency (like that in a single relational database) for eventual consistency. This means that if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. There will be a brief window where different services might see slightly different states of the data. The system is designed to handle this, and for many business processes, this is an acceptable trade-off for the gains in availability and scalability.
The Pillars of Observability: Monitoring Your Python Microservices
In a monolithic application, debugging can be as simple as attaching a debugger or reading a single log file. In a microservices architecture, a single user request might traverse dozens of services. When something fails, how do you find the root cause? This is where observability comes in. It’s a superset of monitoring that allows you to ask arbitrary questions about your system’s state without having to ship new code. It is built on three pillars.
1. Metrics: The Numbers That Matter
Metrics are numerical representations of data measured over time. They are perfect for dashboards and alerting. Key metrics for a service include:
- Request Rate: The number of requests per second.
- Error Rate: The percentage of requests that result in an error.
- Latency: The time it takes to process a request (often measured in percentiles like p95, p99).
Tools: Prometheus is the de facto standard for metrics collection. You can easily instrument your Python applications (Flask, FastAPI, etc.) using the prometheus-client library to expose a /metrics endpoint that Prometheus can scrape.
2. Logging: The Narrative of Your Application
Logs provide a detailed, event-by-event record of what your application is doing. In a microservices world, it’s crucial to centralize these logs. Each log entry should be written in a structured format (like JSON) and include a correlation ID. This ID is generated at the first point of entry (e.g., the API gateway) and passed along in the headers of every subsequent internal request, allowing you to trace the entire journey of a request through your log aggregator.
Tools: The ELK Stack (Elasticsearch, Logstash, Kibana) or EFK (substituting Fluentd for Logstash) are popular choices for centralized logging.
3. Distributed Tracing: Following the Request Journey
Tracing provides the complete picture. It tracks a single request from the moment it enters the system, through every service it touches, to the moment a response is sent back. This is invaluable for identifying performance bottlenecks and understanding complex service interactions.
Tools: OpenTelemetry is emerging as the industry standard for instrumenting applications to generate traces. These traces can then be sent to a backend like Jaeger or Zipkin for visualization. You can see a complete flame graph of a request, showing how much time was spent in each service and in network calls between them.
Deployment and Orchestration Strategies
How you package, deploy, and manage your fleet of microservices is critical for achieving the promised benefits of agility and resilience.
Containerization with Docker
Containers solve the “it works on my machine” problem by packaging an application with all its dependencies (libraries, runtime, system tools) into a single, isolated unit. Docker is the most popular containerization technology. Each microservice should be packaged into its own Docker image.
Example Python Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.9-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the application's code
COPY . .
# Expose the port the app runs on
EXPOSE 8000
# Define the command to run the application
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
Orchestration with Kubernetes (K8s)
Running a few containers is easy. Running hundreds or thousands across a cluster of machines is not. This is where a container orchestrator like Kubernetes becomes essential. Kubernetes automates the deployment, scaling, and management of containerized applications. It provides:
- Self-healing: Automatically restarts containers that fail.
- Service Discovery and Load Balancing: Exposes services with a stable DNS name and distributes traffic among their instances.
- Automated Rollouts and Rollbacks: Allows you to perform zero-downtime deployments and easily roll back to a previous version if something goes wrong.
- Scalability: Allows you to scale services up or down with a single command or automatically based on CPU usage.
Conclusion: Embracing the Complexity
We have journeyed through the most challenging and critical aspects of building a Python microservices architecture. Moving beyond simple service creation, we’ve confronted the realities of a distributed environment. We learned that choosing the right communication pattern—synchronous for directness, asynchronous for resilience—is a foundational decision. We saw how the Saga pattern allows us to maintain data consistency in a world without distributed transactions. We uncovered the necessity of the three pillars of observability—metrics, logs, and traces—to understand and debug our complex systems. Finally, we recognized that modern deployment is inseparable from containerization with Docker and orchestration with Kubernetes.
The Python ecosystem offers a rich set of tools like FastAPI, gRPC, Celery, and OpenTelemetry to implement these advanced concepts effectively. Building a successful microservices architecture is a significant engineering endeavor, but by understanding these core principles and leveraging the right tools, you can create systems that are not only scalable and resilient but also adaptable to the ever-changing demands of your business.


