Advanced Python Async Programming Techniques – Part 4
Welcome back to our comprehensive series on advanced asynchronous programming in Python. In the previous installments, we laid the groundwork, moving from basic coroutines and event loops to more complex patterns like concurrent execution with asyncio.gather(). Now, in Part 4, we venture into the territory that separates proficient async developers from the true experts. This guide delves into the critical patterns and tools necessary for building robust, scalable, and resilient asynchronous applications. We will explore synchronization primitives that prevent race conditions, architect sophisticated data pipelines with queues, and master the art of graceful error handling, timeouts, and task cancellation.
Mastering these concepts is no longer a niche skill; it’s a necessity for modern Python development, especially in areas like high-performance web servers, data streaming platforms, and network services. The techniques covered here will empower you to write code that is not only fast but also stable and predictable under heavy load. For any developer keen on keeping up with the latest “p, y, t, h, o, n, , n, e, w, s,” on high-performance computing, understanding these advanced asyncio features is paramount. Prepare to elevate your Python skills as we dissect the patterns that power production-grade asynchronous systems.
Mastering Asynchronous Control Flow with Synchronization Primitives
While asyncio‘s single-threaded nature prevents the kind of multi-threading race conditions that corrupt memory, it doesn’t eliminate logical race conditions. A logical race condition occurs when the outcome of an operation depends on the unpredictable sequence of events, such as when two coroutines attempt to read, modify, and write to a shared state. Because a coroutine can be paused at any await point, another coroutine can run and interfere with the shared state, leading to inconsistent or incorrect data. This is where synchronization primitives become essential.
The `asyncio.Lock`: Protecting Critical Sections
An asyncio.Lock is the most fundamental synchronization primitive. It ensures that only one coroutine can enter a “critical section” of code at a time. A coroutine acquires the lock before entering the section and releases it upon exit, forcing other coroutines to wait until the lock is available. The most Pythonic way to use a lock is with an async with statement, which guarantees the lock is released even if an error occurs.
Consider a scenario where multiple coroutines increment a shared counter. Without a lock, the operation is not atomic and can lead to incorrect results.
import asyncio
shared_counter = 0
async def unsafe_increment():
global shared_counter
# This read-modify-write operation is not atomic
current_value = shared_counter
await asyncio.sleep(0.01) # Simulate I/O, allowing a context switch
shared_counter = current_value + 1
async def main_unsafe():
tasks = [asyncio.create_task(unsafe_increment()) for _ in range(100)]
await asyncio.gather(*tasks)
print(f"Final counter (unsafe): {shared_counter}") # Likely not 100
# Now, with a lock
shared_counter_safe = 0
lock = asyncio.Lock()
async def safe_increment():
global shared_counter_safe
async with lock:
# This block is now a critical section
current_value = shared_counter_safe
await asyncio.sleep(0.01)
shared_counter_safe = current_value + 1
async def main_safe():
tasks = [asyncio.create_task(safe_increment()) for _ in range(100)]
await asyncio.gather(*tasks)
print(f"Final counter (safe): {shared_counter_safe}") # Always 100
asyncio.run(main_unsafe())
asyncio.run(main_safe())
Bounding Concurrency with `asyncio.Semaphore`
A semaphore is a more generalized version of a lock. While a lock allows only one coroutine access, a semaphore allows a specified number of coroutines to acquire it simultaneously. This is incredibly useful for limiting concurrency to a fixed number, such as when interacting with an external API that has a rate limit or managing a pool of limited resources like database connections.
Imagine a web scraper that needs to download many URLs but wants to limit concurrent downloads to 5 to avoid overwhelming the server or getting IP-banned.
import asyncio
import aiohttp
# Limit concurrent requests to 5
semaphore = asyncio.Semaphore(5)
async def fetch_url(session, url):
async with semaphore:
print(f"Fetching {url}...")
try:
async with session.get(url) as response:
await response.text() # Read the content
print(f"Finished fetching {url}")
return url, "Success"
except Exception as e:
print(f"Failed to fetch {url}: {e}")
return url, "Failed"
async def main():
urls = [f"https://example.com/{i}" for i in range(20)]
async with aiohttp.ClientSession() as session:
tasks = [fetch_url(session, url) for url in urls]
results = await asyncio.gather(*tasks)
print(f"Downloaded {len(results)} pages.")
asyncio.run(main())
In this example, no more than five fetch_url coroutines will execute the code inside the async with semaphore block at any given time, effectively controlling the load on the external server.
Architecting Robust Data Pipelines with `asyncio.Queue`
In many complex applications, coroutines don’t just run independently; they need to communicate and pass data between each other. The producer-consumer pattern is a classic and powerful way to structure this communication. It decouples the task of producing data from the task of consuming it, allowing them to operate at different rates. asyncio.Queue is the perfect tool for implementing this pattern.
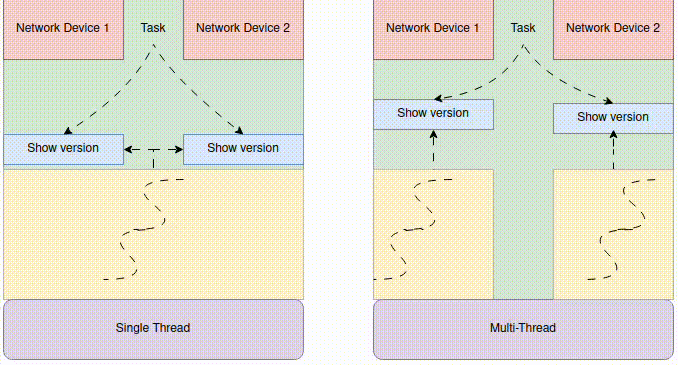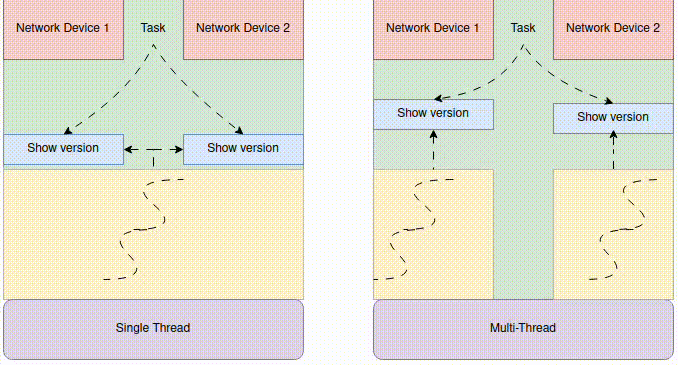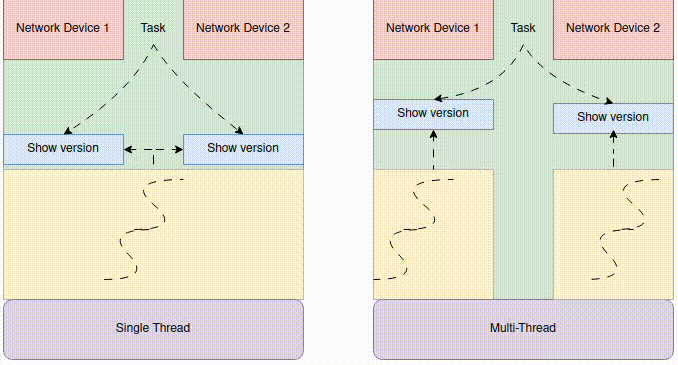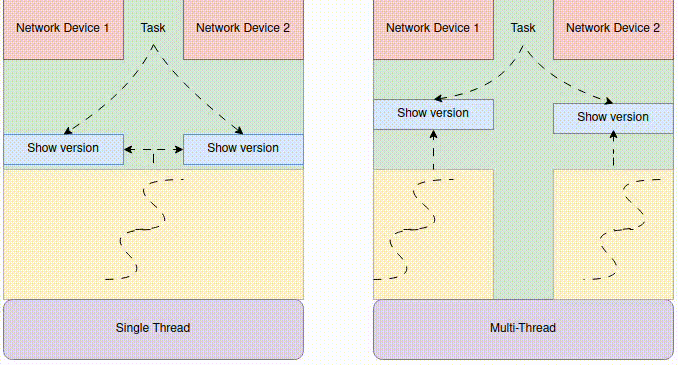
The Producer-Consumer Pattern
A producer is a coroutine that generates or fetches data and puts it into a queue. A consumer is a coroutine that takes data from the queue and processes it. The queue acts as a buffer, smoothing out variations in production and consumption rates and providing a form of “backpressure”—if the consumers can’t keep up, the queue will fill up, and the producers will automatically pause (block asynchronously) when they try to put() an item into a full queue (if a `maxsize` is set).
Implementing a Producer-Consumer System
Let’s build a system with multiple producers fetching data and multiple consumers processing it. This pattern is common in data ingestion pipelines, web scraping clusters, and task processing systems.
import asyncio
import random
async def producer(queue, producer_id):
"""Produces random numbers and puts them in the queue."""
for i in range(5):
item = random.randint(1, 100)
await asyncio.sleep(random.random()) # Simulate work
await queue.put(item)
print(f"Producer {producer_id} produced -> {item}")
async def consumer(queue, consumer_id):
"""Consumes numbers from the queue."""
while True:
item = await queue.get()
# The 'None' sentinel value signals the consumer to stop
if item is None:
# We must put None back for other consumers to see
await queue.put(None)
break
print(f"Consumer {consumer_id} consumed <- {item}")
await asyncio.sleep(random.random() * 2) # Simulate processing
queue.task_done() # Signal that the item has been processed
async def main():
queue = asyncio.Queue()
num_producers = 3
num_consumers = 2
producers = [asyncio.create_task(producer(queue, i)) for i in range(num_producers)]
consumers = [asyncio.create_task(consumer(queue, i)) for i in range(num_consumers)]
# Wait for all producers to finish
await asyncio.gather(*producers)
print("--- All producers have finished ---")
# Signal consumers to stop by putting None for each consumer
for _ in range(num_consumers):
await queue.put(None)
# Wait for all items in the queue to be processed
await queue.join()
# Consumers will now exit, we can cancel them to be sure
for c in consumers:
c.cancel()
print("--- All consumers have finished ---")
asyncio.run(main())
This example demonstrates a graceful shutdown. After producers are done, we put sentinel values (`None`) onto the queue. Each consumer, upon receiving `None`, knows that no more items will arrive and exits its loop. The queue.join() call blocks until every item that was put into the queue has been processed and had task_done() called for it, ensuring a clean and complete shutdown.
Building Resilient Systems: Timeouts, Cancellation, and Error Handling
Production systems must be resilient. They cannot afford to hang indefinitely waiting for a network response or get stuck in a state from which they can't recover. asyncio provides powerful tools for handling these real-world challenges through timeouts and a structured cancellation mechanism.
The Peril of Unbounded Waits: `asyncio.wait_for()`
A coroutine that waits on I/O without a timeout is a potential point of failure. If the remote server never responds, your coroutine will wait forever, consuming resources. The asyncio.wait_for() function wraps a coroutine and raises an asyncio.TimeoutError if it doesn't complete within a specified duration.
async def long_running_operation():
print("Operation started...")
await asyncio.sleep(10) # Simulates a long network call
print("Operation finished.")
async def main():
try:
await asyncio.wait_for(long_running_operation(), timeout=2.0)
except asyncio.TimeoutError:
print("The operation timed out!")
asyncio.run(main())
Understanding Task Cancellation
Cancellation is a core concept in structured concurrency. A parent task might need to cancel its children if it no longer needs their results. When a task is cancelled with task.cancel(), an asyncio.CancelledError is injected into it at the next await point. It is crucial to handle this exception, typically in a finally block, to perform necessary cleanup like closing connections or releasing resources.
async def worker():
try:
while True:
print("Worker is running...")
await asyncio.sleep(1)
except asyncio.CancelledError:
print("Worker was cancelled. Cleaning up...")
# Perform cleanup here, e.g., close a file or network connection
finally:
print("Worker cleanup complete.")
async def main():
task = asyncio.create_task(worker())
await asyncio.sleep(3)
task.cancel()
try:
await task # Await the task to allow cancellation to complete
except asyncio.CancelledError:
print("Main caught the cancellation of the worker.")
asyncio.run(main())
Protecting Critical Operations with `asyncio.shield()`
Sometimes, you have a critical operation that must not be cancelled, even if its parent task is. For example, writing a final status to a database before exiting. asyncio.shield() protects an awaitable from being cancelled. If the task containing the shielded operation is cancelled, the shielded operation continues to run. The cancellation will be raised once the shielded operation is complete.
async def critical_db_write():
print("Starting critical DB write...")
await asyncio.sleep(2) # Simulate a write that cannot be interrupted
print("Critical DB write complete!")
async def main():
task = asyncio.create_task(critical_db_write())
# Shield the task from cancellation
shielded_task = asyncio.shield(task)
# Schedule its cancellation in 1 second
asyncio.get_running_loop().call_later(1, shielded_task.cancel)
try:
await shielded_task
except asyncio.CancelledError:
# This error is raised after the shielded task completes
print("Shielded task was cancelled, but the inner operation finished.")
# The inner task was not cancelled and ran to completion
assert task.done() and not task.cancelled()
asyncio.run(main())
Conclusion: Becoming an Asynchronous Python Expert
In this deep dive, we've moved beyond the fundamentals of async and await to explore the patterns that define robust, production-ready asynchronous Python applications. We've seen how to manage shared state safely with synchronization primitives like Lock and Semaphore, how to build decoupled and scalable data pipelines using the producer-consumer pattern with asyncio.Queue, and how to create resilient systems that can handle timeouts and cancellations gracefully using tools like wait_for and shield. These are not just theoretical concepts; they are the practical building blocks used every day in high-performance systems.
By integrating these advanced techniques into your toolkit, you are equipped to tackle complex concurrency challenges, write more predictable and stable code, and architect systems that can scale efficiently. The journey into asynchronous programming is ongoing, but with these patterns mastered, you are well on your way to becoming an expert in modern, high-performance Python development.


