Django REST Framework Best Practices – Part 4
Welcome back to our comprehensive series on Django REST Framework. In the previous installments, we laid the groundwork for building functional APIs, covering everything from serializers and views to authentication and permissions. Now, in Part 4, we elevate our craft. We move beyond the fundamentals to explore the advanced techniques that distinguish a good API from a truly great, enterprise-grade one. This is where we focus on building APIs that are not only functional but also scalable, maintainable, and highly performant.
Mastering these advanced concepts is crucial for any developer looking to build robust backends capable of handling real-world traffic and complex business logic. In this guide, we will dive deep into three critical areas: supercharging API performance through strategic database querying and caching, mastering advanced serialization for complex data relationships, and future-proofing your API with robust versioning and documentation strategies. These practices are essential for creating APIs that can grow with your application, serve users efficiently, and be a pleasure for other developers to consume. Keeping up with the latest “python news” and framework updates is important, and these topics are consistently at the forefront of modern API development discussions.
Supercharging API Performance: Beyond the Basics
Performance is not a feature; it’s a fundamental requirement. A slow API leads to a poor user experience, increased server costs, and potential scalability bottlenecks. While DRF is performant out of the box, complex applications can easily introduce inefficiencies. Let’s explore how to identify and eliminate them.
Mastering Database Queries: The N+1 Problem
The most common performance killer in DRF is the “N+1 query problem.” This occurs when your code executes one query to fetch a list of objects (the “1”) and then executes N additional queries within a loop to fetch related data for each of those objects. This is especially common with nested serializers.
Consider a simple blog API with Authors and Posts:
# models.py
class Author(models.Model):
name = models.CharField(max_length=100)
class Post(models.Model):
title = models.CharField(max_length=200)
author = models.ForeignKey(Author, related_name='posts', on_delete=models.CASCADE)
If you create a serializer that includes the author’s name in the post list, you might run into trouble.
# serializers.py
class AuthorSerializer(serializers.ModelSerializer):
class Meta:
model = Author
fields = ['name']
class PostSerializer(serializers.ModelSerializer):
author = AuthorSerializer() # Nested serializer
class Meta:
model = Post
fields = ['id', 'title', 'author']
# views.py
class PostListView(generics.ListAPIView):
queryset = Post.objects.all() # The source of the N+1 problem!
serializer_class = PostSerializer
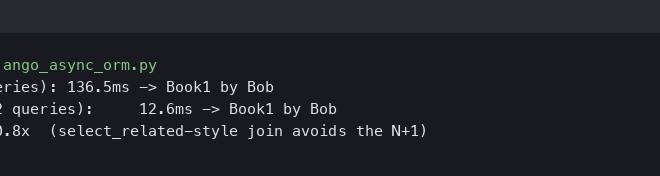
When you hit this endpoint, DRF will first execute one query: SELECT * FROM post;. Then, for each post, the nested AuthorSerializer will trigger another query: SELECT * FROM author WHERE id = ?;. If you have 100 posts, you’ll make 101 database queries! This is incredibly inefficient.
The Solution: Use select_related and prefetch_related in your view’s queryset.
select_related(*fields): Works for foreign key and one-to-one relationships. It performs a SQL JOIN, fetching the related objects in the same database query.prefetch_related(*fields): Works for many-to-many and reverse foreign key relationships. It performs a separate lookup for each relationship and does the “joining” in Python.
Let’s fix our view:
# views.py (Optimized)
class PostListView(generics.ListAPIView):
# Use select_related for the ForeignKey relationship to Author
queryset = Post.objects.select_related('author').all()
serializer_class = PostSerializer
With this single change, Django will now perform a JOIN and fetch all the required data in just one query. If our `Author` model had a `tags` ManyToManyField that we also wanted to include, we would use `prefetch_related`: `Post.objects.select_related(‘author’).prefetch_related(‘tags’).all()`.
Strategic Caching for Read-Heavy Endpoints
For data that doesn’t change frequently, caching is a powerful tool to reduce database load and improve response times dramatically. Django has a robust caching framework that can be easily integrated with DRF.
A simple approach is to use a library like django-cacheops or implement view-level caching manually. Let’s look at a basic example using Django’s built-in tools for an endpoint that lists product categories—data that rarely changes.
from django.utils.decorators import method_decorator
from django.views.decorators.cache import cache_page
from rest_framework import generics
class CategoryListView(generics.ListAPIView):
queryset = Category.objects.all()
serializer_class = CategorySerializer
# Cache this view's response for 15 minutes (900 seconds)
@method_decorator(cache_page(60 * 15))
def get(self, *args, **kwargs):
return super().get(*args, **kwargs)
The first time this endpoint is requested, the view executes, queries the database, serializes the data, and returns the response. Django’s cache middleware then stores this response. Subsequent requests within the 15-minute window will receive the cached response directly, bypassing the view logic, serialization, and database query entirely.
Advanced Serialization: Handling Complex Data and Logic
As your application grows, so does the complexity of its data. DRF’s standard serializers are great, but you’ll inevitably encounter scenarios that require more sophisticated handling of data relationships and business logic.
Writable Nested Serializers
While displaying nested data is easy, writing it is not supported by default. If you try to create a Post and its Author in a single API call using the nested serializer from before, DRF will raise an error. To support this, you must explicitly define the create() and/or update() methods on your serializer.
Imagine an API endpoint where you can create a user profile and their associated address in one POST request.
# serializers.py
class AddressSerializer(serializers.ModelSerializer):
class Meta:
model = Address
fields = ['street', 'city', 'zip_code']
class UserProfileSerializer(serializers.ModelSerializer):
address = AddressSerializer()
class Meta:
model = UserProfile
fields = ['username', 'bio', 'address']
def create(self, validated_data):
address_data = validated_data.pop('address')
address = Address.objects.create(**address_data)
# The **validated_data now only contains UserProfile fields
user_profile = UserProfile.objects.create(address=address, **validated_data)
return user_profile
def update(self, instance, validated_data):
address_data = validated_data.pop('address')
address = instance.address
# Update UserProfile instance
instance.username = validated_data.get('username', instance.username)
instance.bio = validated_data.get('bio', instance.bio)
instance.save()
# Update nested Address instance
address.street = address_data.get('street', address.street)
address.city = address_data.get('city', address.city)
address.zip_code = address_data.get('zip_code', address.zip_code)
address.save()
return instance
This custom logic gives you full control over how related objects are created and updated, enabling more powerful and convenient API endpoints. For very complex nesting, consider a library like drf-writable-nested to automate this process.
Dynamic Fields with `SerializerMethodField`
Sometimes, a field in your API response isn’t a direct mapping of a model field. It might be a computed value, depend on the current user, or require complex logic. This is the perfect use case for `SerializerMethodField`.
Let’s add a field to our PostSerializer that indicates whether the currently logged-in user has “liked” the post.
class PostSerializer(serializers.ModelSerializer):
author = AuthorSerializer(read_only=True)
is_liked_by_user = serializers.SerializerMethodField()
class Meta:
model = Post
fields = ['id', 'title', 'author', 'is_liked_by_user']
def get_is_liked_by_user(self, obj):
# 'obj' is the Post instance
user = self.context['request'].user
if user.is_anonymous:
return False
# Assumes a 'likes' ManyToManyField on the Post model
return obj.likes.filter(id=user.id).exists()
The `get_is_liked_by_user` method is automatically called by DRF for each post. It accesses the request context to get the current user and performs the necessary logic. This pattern is incredibly flexible for adding context-aware data to your API responses.
Future-Proofing Your API: Versioning and Documentation
A public-facing API is a contract. Once consumers start using it, making breaking changes can be disastrous. Versioning allows you to evolve your API without breaking existing client integrations, while documentation makes your API discoverable and usable.
Choosing the Right Versioning Strategy
DRF provides several built-in versioning schemes. The choice depends on your project’s needs.
URLPathVersioning: The version is part of the URL (e.g.,/api/v1/posts/). This is the most explicit and common method. It’s easy for developers to browse and test different versions directly in the browser.NamespaceVersioning: Similar to URL path versioning but uses Django’s URL namespaces.AcceptHeaderVersioning: The client requests a specific version via theAcceptHTTP header (e.g.,Accept: application/json; version=1.0). This is considered more “RESTful” by some, as the URL represents the resource, not its versioned representation. However, it’s harder to test in a browser.QueryParameterVersioning: The version is specified as a query parameter (e.g.,/api/posts/?version=1.0). This is simple but can clutter URLs.
Recommendation: For most projects, URLPathVersioning is the most practical and straightforward choice. It’s easy to understand, implement, and test.
To implement it, configure DRF in your settings.py and update your urls.py:
# settings.py
REST_FRAMEWORK = {
'DEFAULT_VERSIONING_CLASS': 'rest_framework.versioning.URLPathVersioning',
'DEFAULT_VERSION': 'v1',
'ALLOWED_VERSIONS': ['v1', 'v2'],
}
# urls.py
urlpatterns = [
path('api/<str:version>/posts/', PostListView.as_view()),
]
Auto-Generating Interactive Documentation
Good documentation is non-negotiable. Manually writing and maintaining it is tedious and error-prone. Fortunately, modern tools can generate interactive API documentation directly from your code.
The current best-in-class tool for this in the DRF ecosystem is drf-spectacular. It generates an OpenAPI 3.0 schema, which can be used to power beautiful, interactive documentation interfaces like Swagger UI and ReDoc.
Setup is simple:
- Install the package:
pip install drf-spectacular - Add it to
INSTALLED_APPSinsettings.py. - Configure DRF to use it as the default schema class:
# settings.py REST_FRAMEWORK = { 'DEFAULT_SCHEMA_CLASS': 'drf_spectacular.openapi.AutoSchema', # ... other settings } - Add the documentation endpoints to your project’s
urls.py:# urls.py from drf_spectacular.views import SpectacularAPIView, SpectacularRedocView, SpectacularSwaggerView urlpatterns = [ # ... your other urls path('api/schema/', SpectacularAPIView.as_view(), name='schema'), # Optional UI: path('api/schema/swagger-ui/', SpectacularSwaggerView.as_view(url_name='schema'), name='swagger-ui'), path('api/schema/redoc/', SpectacularRedocView.as_view(url_name='schema'), name='redoc'), ]
Now, by visiting /api/schema/swagger-ui/, you and your API consumers will have access to a full, interactive interface where they can see all available endpoints, their required parameters, expected responses, and even try them out directly from the browser.
Conclusion: Building Robust and Scalable APIs
Moving beyond the basics of Django REST Framework unlocks the power to build truly professional, high-quality APIs. By focusing on performance optimization through intelligent querying and caching, you ensure your application remains fast and responsive under load. By mastering advanced serialization techniques, you gain the flexibility to handle any data structure and business requirement your application demands. Finally, by implementing versioning and auto-generating documentation, you create a stable, long-lasting, and developer-friendly API that can evolve gracefully over time.
These practices are not just about writing better code; they are about adopting a mindset of quality, scalability, and maintainability. As you continue your journey with Django and DRF, integrating these advanced strategies into your workflow will significantly elevate the quality of your projects and set you apart as a skilled API developer.