
Machine Learning Model Deployment with Python – Part 3
Welcome back to our comprehensive series on deploying machine learning models in production with Python. In Part 1, we built a basic model and wrapped it in a simple API. In Part 2, we took the first steps toward deployment. Now, in Part 3, we elevate our approach from a functional prototype to a robust, scalable, and maintainable production-grade system. This is where the theoretical meets the practical, and where the “Ops” in MLOps truly comes to life.
This installment is your step-by-step guide to the advanced techniques that separate hobby projects from enterprise-level AI applications. We will dive deep into containerization with Docker, orchestrate our services with Kubernetes, explore high-performance model serving frameworks that go beyond simple Flask APIs, and, most importantly, establish a resilient MLOps lifecycle through monitoring, logging, and automated retraining pipelines. Prepare to transform your deployed model into a living, breathing system that can adapt, scale, and deliver consistent value in the real world.
Containerization and Orchestration: From Code to Cloud-Native
The infamous “it works on my machine” problem has plagued software development for decades, and machine learning is no exception. A model trained with a specific version of Python, TensorFlow, and dozens of other libraries can easily fail in a production environment with slightly different configurations. Containerization solves this problem by packaging our application, its dependencies, and its configuration into a single, isolated, and portable unit.
Why Containerize? The Power of Docker
Docker is the industry standard for containerization. It allows us to create a lightweight, standalone, executable package—a container—that includes everything needed to run an application: code, runtime, system tools, system libraries, and settings. This ensures consistency across development, testing, and production environments.
For a typical Python ML model served via a web framework like FastAPI, a Dockerfile (the blueprint for building a Docker image) might look like this:
# Use an official Python runtime as a parent image
FROM python:3.9-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container at /app
COPY ./requirements.txt /app/requirements.txt
# Install any needed packages specified in requirements.txt
RUN pip install --no-cache-dir --upgrade -r /app/requirements.txt
# Copy the rest of the application's code
COPY . /app
# Expose the port the app runs on
EXPOSE 8000
# Define the command to run the application
# Using gunicorn for a production-ready web server
CMD ["gunicorn", "--workers", "4", "--bind", "0.0.0.0:8000", "main:app"]
This file creates a self-contained environment. It starts from a lean Python base image, sets up a working directory, installs the exact library versions specified in requirements.txt, copies the application code, and defines the command to start a production-grade server like Gunicorn. The resulting container can be run on any machine with Docker installed, guaranteeing that the environment is identical everywhere.
Managing Fleets of Containers with Kubernetes (K8s)
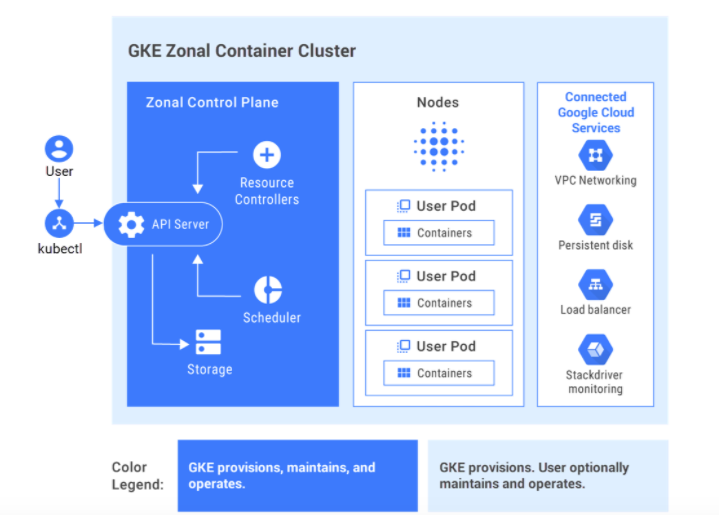
Running one container is simple. But what happens when you need to run ten instances for high availability, automatically scale up to fifty during peak traffic, and perform zero-downtime updates? This is where a container orchestrator like Kubernetes comes in. Kubernetes automates the deployment, scaling, and management of containerized applications.
Key Kubernetes concepts for ML deployment include:
- Pods: The smallest deployable unit in Kubernetes, typically wrapping a single container (e.g., our model API container).
- Deployments: A controller that manages the lifecycle of Pods. It ensures a specified number of replica Pods are running and handles updates using strategies like rolling updates to prevent downtime.
- Services: Provides a stable network endpoint (a single IP address and DNS name) to access a group of Pods. It acts as an internal load balancer, distributing traffic among the model replicas.
- Horizontal Pod Autoscaler (HPA): Automatically scales the number of Pods in a Deployment up or down based on observed CPU utilization or other custom metrics, ensuring your application has the resources it needs without over-provisioning.
By defining our application in Kubernetes manifests (YAML files), we can achieve a self-healing, auto-scaling, and resilient deployment that would be incredibly complex to manage manually.
Beyond Flask: High-Performance Model Serving
While frameworks like Flask and FastAPI are excellent for building APIs, they are general-purpose web frameworks, not specialized for the unique demands of high-throughput, low-latency machine learning inference. For demanding applications, we turn to dedicated model serving frameworks that are optimized for performance.
Dedicated Model Serving Frameworks
These servers are built from the ground up to squeeze every ounce of performance out of your hardware, especially GPUs. In much of the recent python news and MLOps discussions, the focus is on these powerful tools.
- NVIDIA Triton Inference Server: A powerhouse for model serving. It supports nearly every major ML framework (TensorFlow, PyTorch, ONNX, TensorRT), can run multiple models and multiple instances of the same model concurrently on one or more GPUs, and features advanced capabilities like dynamic batching, which groups incoming requests together to maximize GPU throughput.
- TorchServe and TensorFlow Serving: These are the official serving solutions from PyTorch and TensorFlow, respectively. They offer tight integration with their parent frameworks, version management for models, and are highly optimized for performance.
- BentoML & Seldon Core: These are higher-level toolkits that streamline the process of packaging models for serving. They often use high-performance servers under the hood and provide a standardized way to define inference graphs, handle pre/post-processing, and integrate seamlessly with Kubernetes.
Serving Patterns: Online, Batch, and Serverless
Not all predictions need to happen in real-time. Choosing the right serving pattern is critical for cost and efficiency.
- Online (Real-time) Inference: This is the classic API endpoint pattern where a client sends a request and waits for an immediate response. It’s essential for user-facing applications like fraud detection, product recommendations, or search ranking. Low latency is the primary goal.
- Batch Inference: This pattern involves processing large volumes of data offline on a schedule. For example, generating a daily report on customer churn risk or scoring millions of images overnight. This is often orchestrated by workflow tools like Apache Airflow or Kubeflow Pipelines and is optimized for throughput and cost-efficiency rather than latency.
- Serverless Inference: Using platforms like AWS Lambda or Google Cloud Functions, you can deploy your model as a function that is only invoked when a request comes in. This is incredibly cost-effective for models with infrequent or spiky traffic, as you pay only for the compute time you use. However, be mindful of “cold starts” (the initial delay when the function is first invoked) and limitations on package size and execution duration.
The MLOps Lifecycle: Monitoring, Logging, and Automation
Deploying a model is not the end of the journey; it’s the beginning. Models in production are not static. Their performance can and will degrade over time due to changes in the real world. A robust MLOps practice is about building a closed-loop system to detect and correct this degradation.
Monitoring for Decay: Data Drift and Concept Drift
Two silent killers of production models are drift:
- Data Drift: This occurs when the statistical properties of the input data change. For example, a loan approval model trained on pre-pandemic data may perform poorly when it encounters new economic patterns. Monitoring input feature distributions (mean, median, variance) and comparing them to the training data is crucial for detection.
- Concept Drift: This is more subtle; the statistical properties of the data might be the same, but the relationship between inputs and outputs has changed. For instance, what constituted a “spam” email five years ago is very different from today’s sophisticated phishing attempts. Monitoring the model’s key performance indicators (e.g., accuracy, precision, recall) on a stream of newly labeled data is the best way to catch concept drift.
Tools like Prometheus, Grafana, and specialized libraries such as Evidently AI or NannyML are essential for building dashboards that track both system health (latency, error rates) and model-specific metrics, alerting you the moment performance begins to decline.
Automating the Retraining Pipeline
When monitoring detects significant drift or performance degradation, the solution is to retrain the model on new, relevant data. Manually triggering this process is slow and error-prone. The goal is a fully automated retraining pipeline, often built with tools like Kubeflow Pipelines, TFX, or Airflow.
A typical automated pipeline looks like this:
- Trigger: The pipeline is initiated either on a fixed schedule (e.g., weekly) or by an alert from the monitoring system.
- Data Ingestion & Validation: Pulls fresh, labeled data from production logs or a data lake and validates its quality.
- Model Training: Executes the training script on the new data.
- Model Evaluation: Compares the newly trained model against the currently deployed model using a held-out test set. This “challenger vs. champion” evaluation is critical to ensure the new model is actually better.
- Model Registration: If the challenger model wins, it is versioned and saved to a central Model Registry (like MLflow or Vertex AI Model Registry).
- Automated Deployment: The registration of a new model version triggers a CI/CD pipeline (e.g., Jenkins, GitLab CI) to safely roll out the new model, often using a canary deployment strategy.
Strategies for Scaling and Performance
As your application grows, your model serving infrastructure must be able to handle the increased load gracefully. Keeping up with the latest python news on performance optimization is key for any engineer in this field.
Scaling Strategies: Vertical vs. Horizontal
- Vertical Scaling (“Scaling Up”): This involves adding more resources (CPU, RAM, GPU) to the machine(s) running your model. It’s simple to implement but has a physical limit and can become prohibitively expensive.
- Horizontal Scaling (“Scaling Out”): This involves adding more machines (or Pods in Kubernetes) to distribute the load. This is the modern, cloud-native approach. It’s more complex to set up but is more resilient and can scale almost infinitely. Kubernetes’ Horizontal Pod Autoscaler makes this a declarative and automated process.
Canary Deployments and A/B Testing
Deploying a new model version directly to 100% of your users is risky. A subtle bug or unexpected behavior could have a massive impact. A safer approach is a canary deployment:
- Deploy the new model version (the “canary”) alongside the existing version.
- Initially, route a small fraction of live traffic (e.g., 1-5%) to the canary.
- Closely monitor its performance and error rates.
- If the canary performs well, gradually increase its traffic share.
- If issues arise, you can instantly roll back by routing all traffic back to the old version, minimizing the blast radius.
This same mechanism can be used for A/B testing, where you route traffic to two different model versions to empirically determine which one performs better on key business metrics.
Conclusion
Moving from a simple script to a production-grade machine learning system is a significant leap in complexity and capability. It requires a shift in mindset from just building models to building resilient, automated, and observable systems. By embracing containerization with Docker, orchestration with Kubernetes, leveraging high-performance serving frameworks, and adopting a rigorous MLOps culture of monitoring and automation, you can build ML applications that not only work but also thrive and adapt at scale. The principles discussed in this part of our series are the foundation upon which reliable and impactful AI products are built, ensuring your models deliver continuous, measurable value in the ever-changing real world.


