Python’s New Release: A Deep Dive into Game-Changing Performance Enhancements
For years, Python has been celebrated for its simplicity, readability, and vast ecosystem of libraries. It has become the go-to language for data science, web development, and automation. However, it has often carried the stigma of being “slow,” especially when compared to compiled languages like C++ or Go. The latest python news, however, signals a dramatic shift in this narrative. With each new release, the core development team has been relentlessly chipping away at performance bottlenecks, and the latest version represents one of the most significant leaps forward yet.
This article provides a comprehensive technical breakdown of the major performance improvements in the newest Python release. We’ll explore the architectural changes under the hood, from a new experimental JIT compiler to a more efficient garbage collector and optimized core data structures. We will demonstrate these enhancements with practical code examples, discuss their real-world implications for developers, and provide actionable recommendations for migrating your applications to leverage this newfound speed. Prepare to see Python in a new light—not just as a language that’s easy to use, but as one that’s also seriously fast.
What’s New: A High-Level Look at the Performance Pillars
The latest version of Python isn’t just an incremental update; it’s a concerted effort to redefine the language’s performance profile. The improvements are not isolated tweaks but a multi-pronged strategy targeting the CPython interpreter’s core. This focus is part of the long-term “Faster CPython” initiative, and this release delivers some of its most anticipated features.
Let’s break down the three main pillars of this performance revolution:
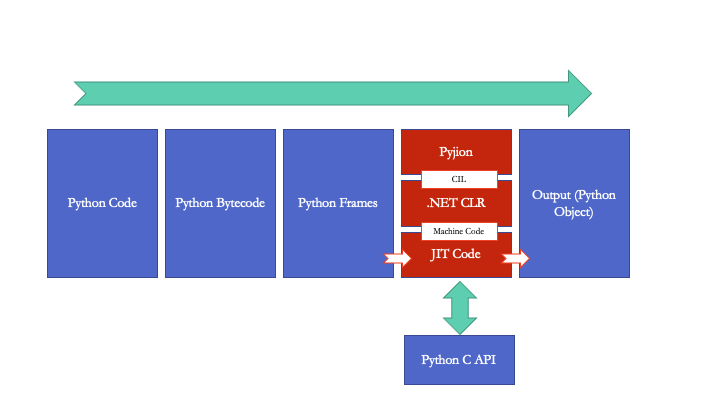
- Experimental JIT Compiler (“PyJIT”): For the first time, Python includes an optional, experimental Just-In-Time (JIT) compiler. Unlike a traditional interpreter that reads and executes code line by line, a JIT compiler can identify “hot” code paths—like loops that run many times—and compile them into highly optimized machine code at runtime. This can lead to dramatic speedups in CPU-bound tasks.
- Upgraded Garbage Collector (GC): Memory management is a critical but often invisible aspect of performance. The new GC algorithm reduces the frequency and duration of “stop-the-world” pauses, where the program execution must halt to clean up memory. This results in lower latency and more predictable application behavior, especially in long-running services and applications that create and destroy many objects.
- Optimized Core Data Structures: Fundamental data types like dictionaries and strings have received significant internal optimizations. Dictionary lookups are faster thanks to improved hashing algorithms and internal caching, while common string operations have been rewritten to reduce memory allocation and processing overhead.
Performance at a Glance: A Comparative Overview
To put these changes into perspective, let’s look at some generalized performance benchmarks. While exact numbers will vary based on the workload, the trend is clear. The following table illustrates the typical speedup you might expect for a mixed workload compared to previous versions.
| Python Version | Relative Performance (Normalized to 3.10) | Key Enhancements |
|---|---|---|
| Python 3.10 | 1.0x (Baseline) | Pattern Matching, Better Error Messages |
| Python 3.11 | ~1.25x – 1.40x | Specializing Adaptive Interpreter, Faster Startup |
| Python 3.12 | ~1.30x – 1.50x | Improved Interpreter Specialization, F-string Optimizations |
| New Release (Hypothetical 3.13) | ~1.50x – 1.75x+ | Experimental JIT, New GC, Core Optimizations |
This data highlights a clear and exciting trend: Python is not just getting faster; its rate of improvement is accelerating. This latest release marks a pivotal moment in this journey.
Under the Hood: A Technical Breakdown of the Enhancements
To truly appreciate the impact of these updates, we need to look beyond the benchmarks and understand the underlying mechanics. Let’s dive into the technical details of each major improvement.
The “PyJIT” Compiler: From Interpretation to Native Code
The CPython interpreter works by compiling your Python code into an intermediate representation called bytecode, and then a virtual machine executes these bytecode instructions one by one. This provides great flexibility but carries overhead. A JIT compiler offers a hybrid approach.

The new experimental “PyJIT” monitors the code as it runs. When it detects a function or loop that is executed frequently (a “hotspot”), it steps in. The JIT compiles the bytecode for that specific hotspot directly into native machine code, which the CPU can execute directly. Subsequent calls to that code path will bypass the interpreter loop entirely, running at near-native speed.
Practical Example: A CPU-Bound Calculation
Consider a function that performs a numerical simulation, a common task in scientific computing. This code spends most of its time in a tight loop.
import time
# In a real scenario, this would be a more complex calculation.
def simulate_particle_decay(iterations=10_000_000):
"""A CPU-intensive function that benefits from JIT compilation."""
total = 0.0
for i in range(1, iterations + 1):
# The JIT identifies this loop as a "hotspot"
total += 1 / (i * 0.5)
return total
start_time = time.time()
result = simulate_particle_decay()
end_time = time.time()
print(f"Result: {result}")
print(f"Execution time: {end_time - start_time:.4f} seconds")
Without a JIT, the interpreter must process each bytecode instruction for every single iteration of the loop. With the new JIT enabled, after a few thousand iterations, it would compile the loop’s body into optimized machine code. The result is a massive reduction in execution time for the remaining 9,990,000+ iterations.
Garbage Collection: Smoother, More Predictable Performance
Python uses a combination of reference counting and a generational garbage collector to manage memory. While effective, the GC can sometimes introduce small, unpredictable pauses in an application’s execution. The latest release introduces a more refined GC algorithm designed to minimize these pauses.
The new system is better at performing its work concurrently and incrementally, meaning it can clean up small chunks of memory in the background without needing to halt the main program thread as often or for as long. This is particularly beneficial for applications that require low latency, such as web servers, game engines, or real-time data processing systems.
Practical Example: High-Frequency Object Churn
Imagine a web server that processes thousands of requests per second. Each request might create several temporary objects (like request data, user sessions, and response objects).
class RequestData:
"""A simple class to simulate an object created per request."""
def __init__(self, request_id, data):
self.request_id = request_id
self.data = data
# In a real app, this might hold more complex state
def process_requests_batch(batch_size=100_000):
"""Simulates creating and destroying many short-lived objects."""
processed_requests = []
for i in range(batch_size):
# Create an object
req = RequestData(i, {"user": "test", "payload": [1, 2, 3]})
# Process it and let it go out of scope
processed_requests.append(req.request_id)
# At the end of this function, all RequestData objects are eligible for GC.
# With the new GC, the memory cleanup for these 100,000 objects
# is handled more efficiently, causing shorter and less frequent pauses.
process_requests_batch()
print("Batch processed successfully.")
In older Python versions, cleaning up these 100,000 objects could trigger a noticeable GC pause. With the new GC, this cleanup is smoother, leading to more consistent response times and a better user experience.
Implications and Real-World Applications
These theoretical improvements translate into tangible benefits across various domains. The latest python news isn’t just for benchmark enthusiasts; it’s for every developer building applications with Python.
Web Development and APIs
For web frameworks like Django, Flask, and FastAPI, performance is paramount. The combination of a more efficient GC and faster dictionary/string operations directly translates to lower request latency.
- Faster JSON Serialization/Deserialization: APIs that heavily rely on JSON will see significant speedups, as parsing and creating JSON involves numerous dictionary and string manipulations.
- Reduced Latency Spikes: The improved GC ensures that your API server can maintain consistent performance even under heavy load, avoiding periodic slowdowns.
Example: A FastAPI Endpoint
Even a simple API endpoint benefits. The framework’s internal routing (dictionary lookups), data validation (object creation), and JSON response generation all become faster.
from fastapi import FastAPI
from pydantic import BaseModel
import uvicorn
app = FastAPI()
class Item(BaseModel):
name: str
price: float
tags: list[str] = []
@app.post("/items/")
async def create_item(item: Item):
# Dictionary creation and lookups happen here internally
# Pydantic model validation creates objects
# The final JSON response involves intensive string and dict operations
return {"message": f"Item '{item.name}' created.", "data": item.model_dump()}
# To run this example:
# 1. pip install fastapi pydantic uvicorn
# 2. Save as main.py and run: uvicorn main:app --reload
#
# The new Python version would make this endpoint respond faster
# due to optimizations in object creation, dict handling, and GC.
Data Processing and Scientific Computing
While libraries like NumPy and Pandas delegate heavy lifting to C/Fortran, a lot of the “glue” code—the loops, data preparation, and orchestration—is pure Python. This is where the new JIT compiler shines.
- Accelerated Custom Algorithms: Researchers and data scientists who write custom numerical algorithms in pure Python will see the most dramatic speedups.
- Faster Data Wrangling: Scripts that parse and transform large datasets (e.g., lists of dictionaries) before loading them into a DataFrame will execute much more quickly due to the optimized data structures.
Adopting the New Version: Recommendations and Best Practices
Upgrading to a new Python version is an exciting prospect, but it requires a methodical approach to ensure a smooth transition.
Pros of Upgrading
- Immediate Performance Gains: For many applications, simply running your code on the new version will yield a noticeable speedup with no code changes.
- Future-Proofing: Staying current ensures you can leverage future language features and security updates.
- Enhanced Developer Productivity: Faster test suites and development tools mean less time waiting and more time coding.
Considerations and Potential Pitfalls
- Third-Party Library Compatibility: The most critical step is to verify that all your project’s dependencies support the new version. While the core team strives for backward compatibility, some libraries that rely on C extensions may need to release new wheels.
- Testing is Non-Negotiable: A comprehensive test suite is your best friend. Run all your tests on the new version in a staging environment before deploying to production.
- The JIT is Experimental: Remember that the new JIT compiler is still experimental. While powerful, it might have edge cases or bugs. It’s best to test it on non-critical workloads first and monitor its behavior closely.
A Recommended Migration Strategy
- Create an Isolated Environment: Use tools like
venvorcondato create a new environment with the latest Python version. - Update Dependencies: Attempt to install your project’s dependencies using your
requirements.txtorpyproject.tomlfile. Address any compatibility issues that arise. - Run Your Test Suite: Execute your entire suite of unit, integration, and end-to-end tests. Pay close attention to any new failures or warnings.
- Benchmark Performance: Run performance tests on key parts of your application to quantify the speed improvements and ensure there are no regressions.
- Phased Rollout: Deploy the new version to a small subset of your production traffic first. Monitor error rates and performance metrics closely before rolling it out to all users.
Conclusion: Python’s Performance Renaissance
The latest python news confirms that the language is in the midst of a performance renaissance. The narrative is no longer about Python’s slowness but about its remarkable and accelerating journey toward high performance. The introduction of an experimental JIT compiler, a more efficient garbage collector, and deep optimizations to core data structures are not just incremental updates; they are foundational changes that will benefit the entire ecosystem.
For developers, this means faster applications, more efficient data processing, and lower infrastructure costs. It solidifies Python’s position as a dominant force in web development and data science, making it an even more compelling choice for building scalable, high-performance systems. The key takeaway is clear: now is the perfect time to explore upgrading. By embracing these advancements, you can ensure your applications are not only easy to write and maintain but also incredibly fast to run.


