
Elevating RAG Development: LlamaIndex Vibe Coding, SQL Integration, and the Modern Python Stack
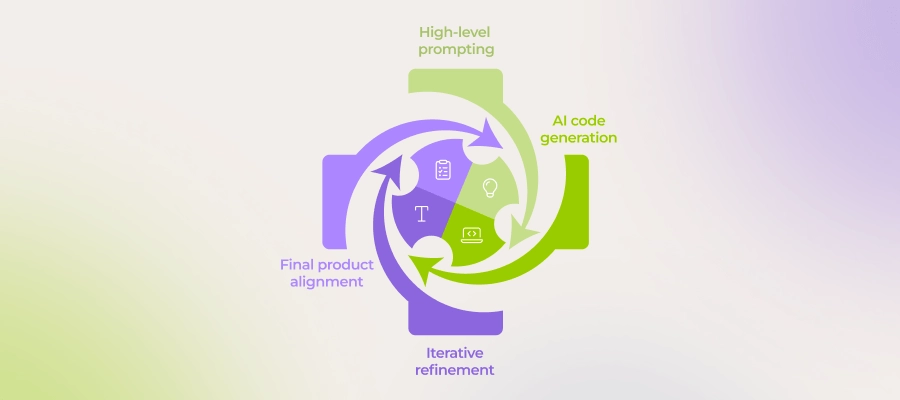
The landscape of Generative AI development is shifting rapidly. We have moved past simple chatbots into the era of “Vibe Coding”—a workflow where developers leverage advanced coding agents like Cursor, Claude, and GitHub Copilot to accelerate architecture and implementation. However, a persistent challenge remains: these AI agents often rely on training data that lags behind the bleeding edge of library updates. This is particularly critical for fast-moving frameworks like LlamaIndex, where new abstractions for agents, workflows, and vector storage are released weekly.
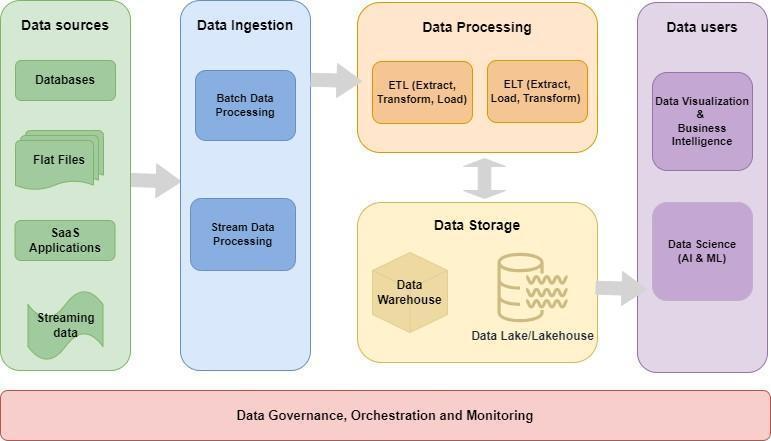
Recent developments in the LlamaIndex ecosystem have focused on bridging this gap, providing toolkits designed to inject the absolute latest documentation and API references directly into the context of your coding assistants. This ensures that when you are building complex RAG (Retrieval-Augmented Generation) applications, your AI pair programmer isn’t hallucinating deprecated methods. In this article, we will explore how to leverage this modern “vibe coding” approach to build robust, production-grade LlamaIndex applications backed by powerful SQL architectures. We will dive deep into schema design, vector indexing strategies, and the integration of the modern Python ecosystem—including tools like Polars dataframe, DuckDB python, and FastAPI news—to create high-performance AI solutions.
Section 1: The Foundation – Structured Data and SQL Schemas in RAG
While LlamaIndex is renowned for handling unstructured data, the most powerful enterprise applications often require a hybrid approach. “Vibe coding” isn’t just about writing Python faster; it’s about architecting systems where structured business data lives alongside semantic vector embeddings. When using coding agents to scaffold your application, providing them with a rigorous SQL schema is the first step toward success.
Modern RAG applications often utilize PostgreSQL with pgvector or similar SQL-based vector stores. This allows for transactional integrity—a critical feature often missing in purely NoSQL vector databases. By defining a strict schema, we ensure that metadata filtering (e.g., filtering documents by user ID or date) is performant and reliable.
Below is a practical example of a robust SQL schema designed for a LlamaIndex-powered financial analysis application. This schema handles document chunks, vector embeddings, and associated metadata, optimized for hybrid search.
-- Enable the vector extension for embedding storage
CREATE EXTENSION IF NOT EXISTS vector;
-- Create a schema for our RAG application
CREATE SCHEMA IF NOT EXISTS finance_rag;
-- Table for storing source documents (e.g., PDF reports, Earnings Calls)
CREATE TABLE finance_rag.source_documents (
doc_id SERIAL PRIMARY KEY,
external_id VARCHAR(255) UNIQUE NOT NULL,
title VARCHAR(500),
upload_date TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
doc_metadata JSONB DEFAULT '{}'::jsonb
);
-- Table for storing text chunks and their embeddings
-- LlamaIndex typically uses 1536 dimensions for OpenAI models
CREATE TABLE finance_rag.document_nodes (
node_id UUID PRIMARY KEY, -- LlamaIndex uses UUIDs for node tracking
doc_id INTEGER REFERENCES finance_rag.source_documents(doc_id) ON DELETE CASCADE,
text_content TEXT NOT NULL,
embedding vector(1536), -- Vector column for semantic search
node_metadata JSONB,
created_at TIMESTAMP DEFAULT NOW()
);
-- Indexing Strategy:
-- 1. GIN index on JSONB for fast metadata filtering (e.g., "Find all nodes from Q3 2024")
CREATE INDEX idx_node_metadata ON finance_rag.document_nodes USING GIN (node_metadata);
-- 2. HNSW Index for approximate nearest neighbor search (Vector Search)
-- This is crucial for performance when scaling to millions of chunks
CREATE INDEX idx_embedding_hnsw ON finance_rag.document_nodes
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);When using a “vibe coding” workflow, you would feed this schema into your agent (e.g., Claude or Cursor) along with the latest LlamaIndex SQL documentation. This allows the agent to generate the precise Python SQLAlchemy models or SQLModel classes that map to this structure, ensuring your application code is perfectly synchronized with your database architecture.
Section 2: Bridging Python and SQL with LlamaIndex
Executive leaving office building – Exclusive | China Blocks Executive at U.S. Firm Kroll From Leaving …
Once the schema is established, the next challenge is querying this data effectively. LlamaIndex provides powerful abstractions like the NLSQLTableQueryEngine (Natural Language to SQL) and VectorStoreIndex backed by SQL. Recent LlamaIndex news highlights improvements in how these engines handle complex joins and context window management.
In the context of modern Python development, we are seeing a shift away from standard heavy ORMs towards faster, async-capable tools. Integrating DuckDB python for local analytical processing or Ibis framework for backend-agnostic queries is becoming common. Furthermore, with GIL removal on the horizon in newer Python versions (Free threading), managing database connections efficiently is more important than ever.
Here is how you might configure a LlamaIndex application to interact with the SQL schema defined above, utilizing a transaction block to ensure data consistency during ingestion. This example demonstrates how to handle document insertion atomically.
import os
from sqlalchemy import create_engine, text
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.postgres import PGVectorStore
from llama_index.core.schema import TextNode
# Database connection URL
DB_URL = "postgresql://user:password@localhost:5432/finance_db"
def ingest_documents_transactional(nodes):
"""
Ingests nodes into the SQL vector store using a transaction.
This ensures that either all nodes are inserted, or none are,
preventing partial states in your RAG application.
"""
engine = create_engine(DB_URL)
# Initialize PGVectorStore (LlamaIndex wrapper)
vector_store = PGVectorStore.from_params(
database="finance_db",
host="localhost",
password="password",
port=5432,
user="user",
table_name="document_nodes",
schema_name="finance_rag",
embed_dim=1536
)
# Manual Transaction Management for custom pre-processing
with engine.begin() as connection:
try:
# Example: Clean up old nodes for a specific document before re-ingestion
# This is a raw SQL execution mixed with LlamaIndex logic
doc_id_to_update = nodes[0].metadata.get('doc_id')
if doc_id_to_update:
delete_query = text("""
DELETE FROM finance_rag.document_nodes
WHERE (node_metadata->>'doc_id')::int = :doc_id
""")
connection.execute(delete_query, {"doc_id": doc_id_to_update})
print(f"Cleaned up old nodes for doc_id {doc_id_to_update}")
# Note: The actual vector insertion is typically handled by the VectorStore abstraction,
# but understanding the underlying transaction context is vital for 'Vibe Coding'
# when you need to extend functionality.
# Create storage context
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Build index (persists to DB)
index = VectorStoreIndex(nodes, storage_context=storage_context)
print("Transaction committed successfully.")
except Exception as e:
print(f"Transaction rolled back due to error: {e}")
raise
# Example usage with dummy nodes
# nodes = [TextNode(text="Q3 revenue increased...", metadata={"doc_id": 101})]
# ingest_documents_transactional(nodes)This code snippet illustrates a critical best practice: mixing high-level LlamaIndex abstractions with low-level SQL control. By providing this pattern to your coding agent, you can ask it to scaffold complex ingestion pipelines that are robust against failures.
Section 3: Advanced Querying and Data Retrieval
The true power of LlamaIndex shines when you combine semantic search with structured SQL filtering. In a “vibe coding” session, you might instruct your agent to “create a query engine that finds documents about ‘inflation’ but only from the last fiscal quarter.” To achieve this, the underlying system must generate SQL that combines vector distance calculations with standard WHERE clauses.
Furthermore, the Python ecosystem surrounding data retrieval is evolving. We are seeing increased adoption of PyArrow updates for efficient memory transfer and Polars dataframe for post-processing retrieval results. Even Marimo notebooks are gaining traction as a reactive alternative to Jupyter for testing these queries.
Let’s look at a complex SQL query that a LlamaIndex engine might generate (or that you might hand-optimize) to perform a hybrid search. This query calculates cosine similarity while strictly enforcing metadata constraints.
-- Complex Hybrid Query: Semantic Search + Metadata Filtering + Time Decay
-- This query finds relevant chunks but boosts newer documents
WITH vector_search AS (
SELECT
node_id,
doc_id,
text_content,
node_metadata,
created_at,
-- Calculate Cosine Distance (1 - Cosine Similarity)
(embedding <=> '[0.012, -0.023, ...]'::vector) as cosine_distance
FROM
finance_rag.document_nodes
WHERE
-- Metadata Filter: Only look at 'Analyst Reports'
node_metadata @> '{"category": "Analyst Report"}'
),
ranked_results AS (
SELECT
*,
-- Calculate a score: Similarity (1 - distance) weighted by recency
(1 - cosine_distance) *
CASE
WHEN created_at > NOW() - INTERVAL '30 days' THEN 1.2 -- Boost recent docs
ELSE 1.0
END as final_score
FROM
vector_search
WHERE
cosine_distance < 0.25 -- Threshold for relevance
)
SELECT
doc_id,
left(text_content, 200) as snippet,
final_score
FROM
ranked_results
ORDER BY
final_score DESC
LIMIT 5;This SQL snippet demonstrates logic that goes beyond simple vector retrieval. It introduces a "recency boost," a common requirement in news or finance apps. By understanding this SQL structure, you can prompt your LlamaIndex agent to implement AutoRetriever classes that dynamically construct these types of filters based on user queries.

Executive leaving office building - After a Prolonged Closure, the Studio Museum in Harlem Moves Into ...
Section 4: Optimization, Tooling, and Best Practices
Modern Python Tooling
To support high-performance LlamaIndex applications, the surrounding infrastructure must be modern. The days of simple pip install are evolving. Developers are now turning to the Uv installer and Rye manager for lightning-fast dependency resolution, or PDM manager and Hatch build for robust project management. When building your RAG agent, ensure your environment is configured with Type hints and checked with MyPy updates to prevent runtime errors.
Security is also paramount. With the rise of Malware analysis in open-source packages, using tools that check PyPI safety is non-negotiable. Additionally, integrating SonarLint python and the Ruff linter (which has largely superseded Flake8) ensures your code remains clean and maintainable. For web-facing RAG apps, frameworks like Litestar framework and Django async are providing excellent alternatives to Flask, while Reflex app and Flet ui allow for building pure Python frontends.
Performance Tuning with SQL
Executive leaving office building - Exclusive | Bank of New York Mellon Approached Northern Trust to ...
As your dataset grows, simple queries will slow down. You must implement database maintenance strategies. Here is a SQL snippet for maintaining the health of your vector index, which is crucial for sustained performance in a production LlamaIndex app.
-- Maintenance Transaction for Vector Indexes
BEGIN;
-- 1. Update optimizer statistics to ensure the query planner makes good decisions
ANALYZE finance_rag.document_nodes;
-- 2. Adjust HNSW parameters for the session to prioritize recall over speed during a bulk re-index
SET LOCAL hnsw.ef_search = 100;
-- 3. Example of a Materialized View for frequent aggregations
-- If your dashboard frequently asks "How many documents per category?", cache it.
CREATE MATERIALIZED VIEW IF NOT EXISTS finance_rag.category_stats AS
SELECT
node_metadata->>'category' as category,
COUNT(*) as chunk_count,
AVG(LENGTH(text_content)) as avg_chunk_len
FROM
finance_rag.document_nodes
GROUP BY
node_metadata->>'category';
-- Refresh the view
REFRESH MATERIALIZED VIEW finance_rag.category_stats;
COMMIT;This maintenance routine ensures that the Local LLM or Edge AI components interacting with your database receive responses within milliseconds, maintaining the illusion of instant intelligence.
Conclusion
The convergence of "Vibe Coding" tools—which inject up-to-date documentation into AI agents—and robust SQL backends represents the new standard for building LlamaIndex applications. We are no longer just scripting; we are orchestrating complex interactions between Large Language Models and structured enterprise data. By mastering the SQL layer (schemas, transactions, and indexing) and leveraging the latest Python ecosystem advancements (from Mojo language concepts to PyTorch news), developers can build RAG systems that are not only intelligent but also scalable, secure, and maintainable.
As you move forward, remember that the most effective coding agents are those fed with the best context. Keep your documentation references fresh, your SQL schemas strict, and your Python environment modern. Whether you are exploring LangChain updates, experimenting with Python quantum computing via Qiskit news, or simply optimizing a Scrapy updates pipeline, the principles of structured data integration remain the bedrock of successful AI engineering.


