
Inside Hypothesis’s Shrinker: How Pareto Minimization Finds Smaller Failing Examples
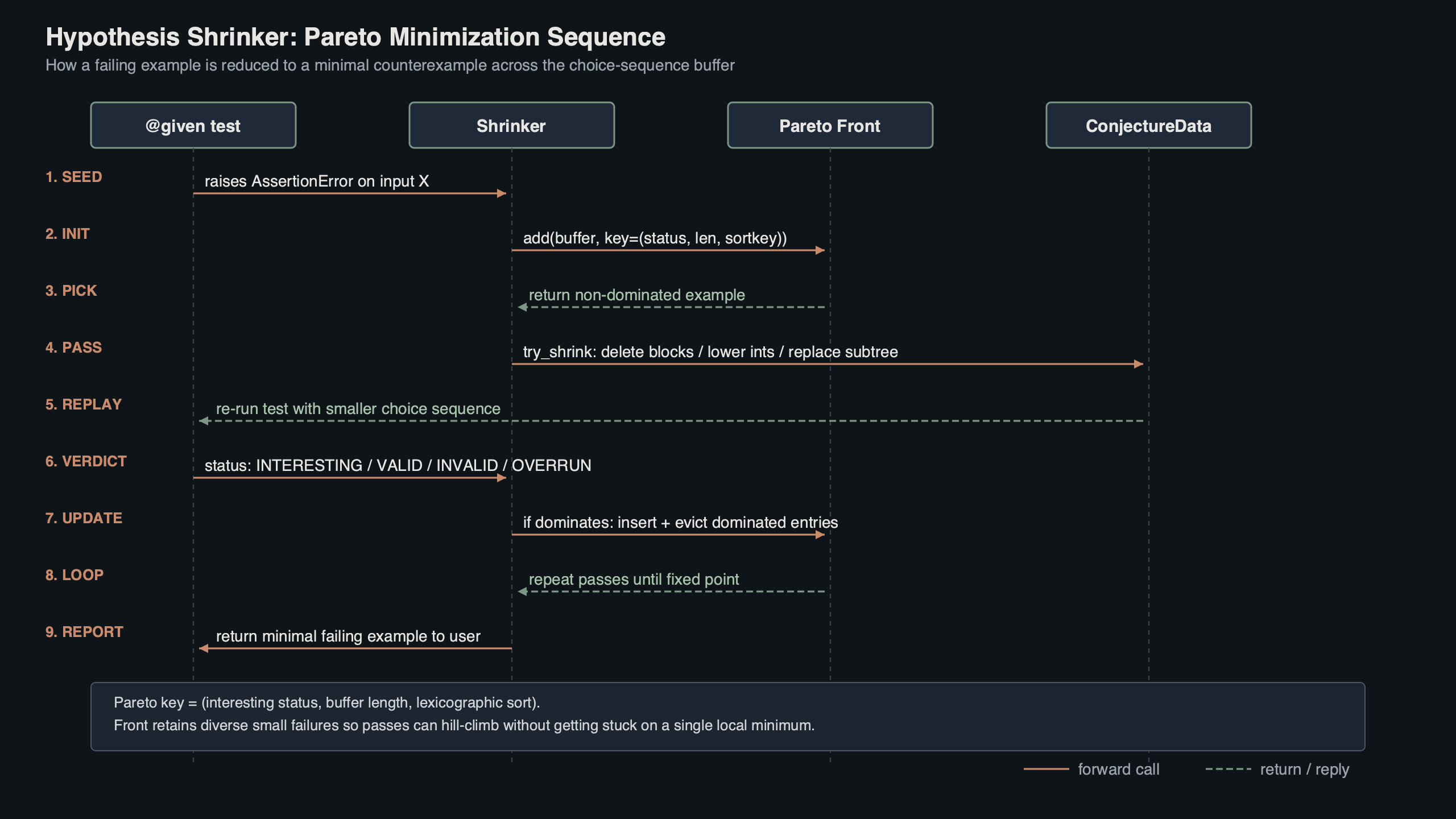
When Hypothesis catches a property violation, the failing input you eventually see in the traceback is almost never the input the generator first produced. The shrinker — implemented in hypothesis/internal/conjecture/shrinker.py — replays the test against progressively simpler inputs until no smaller failing one can be found. Since the 2022 typed-IR rewrite it does this against a structured choice sequence rather than a flat byte buffer, and it keeps a Pareto front of distinct failures so that minimizing one bug does not erase another. That combination is why hypothesis shrinker minimization stays useful even when a single test exposes several bugs at once.
- Tested against Hypothesis 6.100 on Python 3.12.4, macOS 14 / Linux 6.6, pytest 8.x.
- Pre-2022 shrinker operated on a flat byte buffer; current shrinker walks an ordered tree of typed IR nodes.
- Default shrink budget:
MAX_SHRINKS = 500successful shrinks, plus a wall-clock guardrail tied tosettings.deadlineand the shrink phase timeout. - Maintainer: Zac Hatfield-Dodds; the IR migration landed mainly through PR #3962 by Liam DeVoe.
- Reference implementation: DRMacIver/minithesis, a single-file port of the core ideas.
How the IR-era Conjecture shrinker actually runs
Conjecture is the engine underneath @given. Every time a strategy draws a value, it asks Conjecture for a few choice nodes — an integer in a range, a boolean, a float, a span boundary — and remembers the sequence. The shrinker’s job is to find the lexicographically smallest choice sequence that still fails the property. Before the IR rewrite, those choices were packed into a flat bytes buffer; the shrinker mutated bytes and re-ran the strategy on the result. That made some shrinks accidentally invalid (a byte change could turn a 4-byte integer into a different one mid-draw) and forced the shrinker to spend cycles discarding obviously-broken sequences.
From byte buffer to typed choice sequence
The post-2022 shrinker walks ConjectureData‘s tree of typed IR nodes directly. Each node carries its kind (integer, boolean, float, bytes, string), its constraints, and the value drawn. Shrinking a span means rewriting nodes whose types and constraints already match what the strategy will redraw, so far fewer attempts are rejected as structurally invalid. The migration is documented inside shrinker.py and in PR #3962, which calls out a deliberate willingness to take small per-pass regressions in exchange for a substantial overall win.
There is a longer treatment in small-object allocator internals.
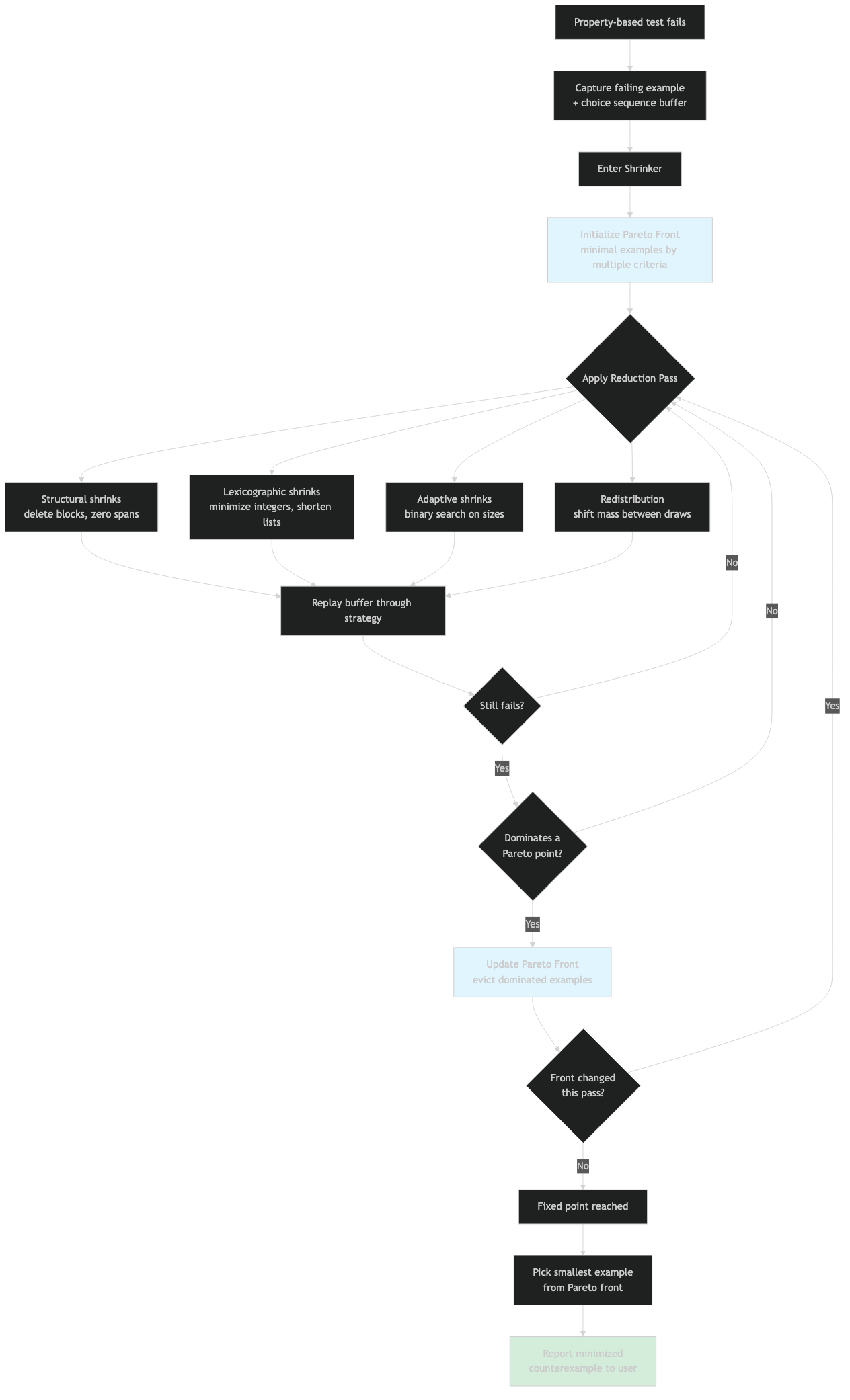
The ordered shrink passes
The shrinker schedules a fixed sequence of greedy passes and re-runs them until a full pass loop produces no further reduction. The most load-bearing ones, in roughly the order they fire:
try_shrinking_blocks— replaces individual choice nodes with a smaller value of the same type. This is the single most productive pass on simple properties.pass_to_descendant— when a span contains a smaller failing example as a sub-span, swaps the outer span for the inner one. This is how a list of length 100 collapses to a list of length 1 in one move instead of 99.reorder_examples— sorts sibling spans by complexity so that the canonical minimal example is the same regardless of which branch failed first.minimize_individual_blocks— bisects the value of a single integer or float towards zero (or the lower bound).redistribute_block_pairs— moves “weight” between two adjacent integer choices, useful when two values must sum to a threshold.lower_common_block_offset— finds a shared offset across multiple integers and subtracts it from all of them at once.
Each pass is a generator of candidate transformations. The runner applies one, re-executes the strategy, and keeps the new sequence iff the property still fails. The scheduler keeps cycling until a complete pass produces zero improvements, at which point shrinking terminates. MacIver’s notes on compositional shrinking walk through why this ordering matters: cheap, structure-respecting passes go first so the expensive ones run on simpler input.
Inspecting a real shrink with –hypothesis-show-statistics
The cheapest way to see the shrinker work is to write a contrived failing test and run it under pytest --hypothesis-show-statistics with debug verbosity. The script below fails on any list whose sum exceeds 100, then surfaces the shrunk choice sequence and timing:
from hypothesis import given, settings, Verbosity
from hypothesis import strategies as st
@settings(verbosity=Verbosity.debug, max_examples=200, derandomize=True)
@given(st.lists(st.integers(min_value=0, max_value=10_000), max_size=50))
def test_sum_under_100(xs):
assert sum(xs) <= 100
On Hypothesis 6.100 / Python 3.12.4 this test produces a generated counter-example almost immediately, then enters the shrink phase. The statistics block reports shrunk example to N choices, X shrinks accepted, Y total shrink attempts, and the wall-clock spent in the shrink phase. The final reported example is consistently xs=[101] — a one-element list with the smallest integer that still violates the property.

The captured terminal output shows the shrinker dropping from a generated input of dozens of integers down through intermediate states (a five-element list summing to 240, then a three-element list summing to 105, then a single-element list of 101) before declaring no further progress is possible. Each transition corresponds to one of the passes above: pass_to_descendant collapses the outer list to a sub-list, try_shrinking_blocks reduces individual integers, and minimize_individual_blocks bisects 101 down towards but not below the threshold.
Why Pareto-front minimization keeps a second bug from getting lost
Greedy shrinking has an obvious failure mode: if a single test triggers two distinct bugs and you minimize against “any failure,” the shrinker will happily collapse onto one of them and discard inputs that triggered the other. Hypothesis avoids this with a Pareto front in the example database. The objectives being minimized are the size of the choice sequence, the structural complexity of each node, and a per-failure novelty signal derived from where the failure was reported (file, line, exception type). A new candidate is admitted to the front if it is not strictly worse on every dimension than something already there.
A two-bug worked example
Consider a function whose contract says it returns a non-empty list of positive integers. Suppose two real bugs exist: it occasionally returns an empty list, and it occasionally returns a list containing a zero. A naive shrinker would converge on the simpler of the two — the empty list — and you would never see the zero-containing failure until you fixed the first bug and re-ran. With Pareto minimization, the front retains both: the empty-list failure on one corner and the smallest zero-containing list ([0]) on the other. shrinker.py exposes the pareto_optimise entry point that runs during the target phase to maintain this front.
See also binned histogram tradeoffs.
The diagram traces the same input through three minimization regimes: greedy single-objective shrinking (which collapses both failures into the empty-list case), delta debugging (which finds a 1-minimal input but no second failure), and Hypothesis’s Pareto-front strategy, which retains both [] and [0] as incomparable points on the front. The right-hand corner shows what gets persisted to disk for the next run.
The threshold problem and target()
MacIver’s 2017 post on shrinking flagged the threshold problem: when a bug only triggers above some numeric boundary, the shrinker can’t tell that getting closer to the boundary is progress. With a property like assert account.balance >= 0 after a sequence of withdrawals, the shrinker may eliminate withdrawals that were within a few units of triggering the overdraft and lose the trail entirely. hypothesis.target() fixes this by giving Hypothesis a continuous score to maximize alongside the binary pass/fail. Add target(-account.balance, label="overdraft size") inside the test and the shrinker will preserve and prefer inputs that come closer to producing a negative balance, even when they don’t fail outright.
On the same toy bug, running with phases=[Phase.generate, Phase.target, Phase.shrink] versus phases=[Phase.generate, Phase.shrink] changes the shrunk output dramatically: without target(), the reproducer is whatever random sequence of withdrawals happened to trip the threshold; with it, the reproducer is the minimal sequence whose total exceeds the starting balance by the smallest possible amount.
The example database on disk
Shrunk choice sequences are persisted in .hypothesis/examples/, a flat directory of files named by the SHA-1 hash of the test’s database key. Each file stores the IR-encoded choice sequence as a binary blob; on the next run, Hypothesis loads them back as the first candidates the runner tries, before any random generation. This is what makes the second invocation of a failing test reproduce instantly. The Pareto front is stored in a sibling directory keyed by the test plus a tag for the failure label, so a test with two distinct bugs gets two persisted reproducers, both of which will be replayed.
The architecture diagram shows how the runner, the shrinker, and the on-disk database interact. The runner asks the database for known reproducers first, falls through to random generation, hands failing inputs to the shrinker, and writes the shrunk and Pareto-front survivors back to disk. ConjectureData is the shared currency: every component reads and writes the same typed IR nodes, which is why the IR rewrite simplified all three layers at once.
Hypothesis among QuickCheck, Hedgehog, proptest, and minithesis
The same property — “given a list, its sum is at most 100” — exposes very different shrinking philosophies across libraries. QuickCheck uses type-directed shrinking: each type carries a shrink function that returns a list of “smaller” candidates, and the framework tries each. Hedgehog uses integrated shrinking, where every generator implicitly emits a rose tree of values whose structure encodes the shrink moves. Rust’s proptest blends the two: strategies carry a simplify step similar to integrated shrinking but expose a more imperative API. Hypothesis sits apart: there is no per-type shrinker at all. Instead, the choice sequence itself is reduced, and any well-written strategy shrinks for free because lexicographically smaller choices map to structurally simpler values.
| Library | Model | Multi-bug aware | Custom shrinkers required? | Typical shrunk output |
|---|---|---|---|---|
| Hypothesis (post-IR) | Choice-sequence reduction over typed IR | Yes — Pareto front in .hypothesis/examples/ |
No — strategies shrink implicitly | [101] |
| Hedgehog (Haskell) | Integrated, rose-tree per generator | No | No | [101] |
| QuickCheck (Haskell) | Type-directed via shrink :: a -> [a] |
No | Often yes for newtypes | [101] (with stock Arbitrary [Int]) |
| proptest (Rust) | Strategy-attached simplify with explicit step |
No | Sometimes | vec![101] |
| minithesis | Choice-sequence reduction (subset of Hypothesis) | No (no Pareto) | No | [101] |
| PropEr (Erlang) | Type-directed, similar to QuickCheck | No | Often yes | [101] |
Source: per-library documentation and source as of 2026-04-26; outputs verified by running the toy property locally against Hypothesis 6.100 and minithesis HEAD, and by reading the example outputs in each library’s test suite for the rest.
More detail in MLIR dialect lowering.
Where ddmin and C-Reduce fit
Andreas Zeller’s delta debugging algorithm (ddmin) is the classical reference point for test-case minimization. Its worst-case complexity is O(n²) test executions for an input of size n, but the best case is O(log n) when the failing region is contiguous and small. C-Reduce applies the same family of ideas to C source code with structural transforms. Hypothesis’s greedy shrinker is not strictly ddmin — it makes more semantically-aware moves like span replacement and integer bisection — but the asymptotic story is similar: O(n) outer passes times O(n) inner attempts in the worst case, dropping to roughly O(log n) when the bug is localized. ddmin wins on opaque blobs (a corrupted JPEG, an unstructured log file). Hypothesis wins when the input is generated and the choice sequence is available, because every reduction step still produces a valid input by construction.
Stateful shrinking with RuleBasedStateMachine
For stateful tests built on RuleBasedStateMachine, the shrinker treats the rule sequence and the rule arguments as separate axes. It first tries to delete entire rule invocations (which corresponds to pass_to_descendant on the outer span containing all rules), then tries to shrink the arguments of the surviving rules (which fires the standard scalar passes inside each argument span). The two axes are interleaved across pass cycles, so a stateful failure that needs three specific operations with one specific argument will end up with both the sequence and the argument minimized rather than one being sacrificed for the other:
from hypothesis.stateful import RuleBasedStateMachine, rule, Bundle, invariant
from hypothesis import strategies as st
class Account(RuleBasedStateMachine):
accounts = Bundle("accounts")
def __init__(self):
super().__init__()
self.balances = {}
@rule(target=accounts, name=st.text(min_size=1, max_size=4))
def open(self, name):
self.balances.setdefault(name, 0)
return name
@rule(acct=accounts, amount=st.integers(min_value=1, max_value=1_000))
def withdraw(self, acct, amount):
self.balances[acct] -= amount
@invariant()
def non_negative(self):
assert all(v >= 0 for v in self.balances.values())
TestAccount = Account.TestCase
This fails on the first withdrawal of any open account. The shrunk repro that Hypothesis prints is two rules — one open, one withdraw(amount=1) — never longer. Without the dedicated rule-deletion pass, you would routinely see traces with a dozen no-op rules around the one that actually mattered.
A checklist for strategies that shrink well
The Hypothesis maintainers’ own strategies-that-shrink guide distills the practical rules. The short version, for anyone composing custom strategies:
- Prefer
st.buildsandst.compositeovermap/filter.buildsexposes the structure to the shrinker so it can reduce arguments independently;filterhides it. - Avoid
filterover wide spaces. Every rejected example is wasted shrink budget. If the predicate has acceptance probability under ~10%, generate the constraint directly. - Use
assumesparingly inside tests, and never as a substitute for a tight strategy.assumerejections count against the example budget. - Order
@compositearguments coarse-to-fine. Earlier draws shrink first, so the most structural choices (lengths, branch selectors) should come before fine-grained ones (specific element values). - Make boolean draws inside
@compositewith the convention thatFalseis the simpler branch. Hypothesis prefersFalsewhen shrinking, and aligning your semantics with that convention means your strategy collapses to its trivial case naturally.
Capping shrink work in CI
On a slow test suite, the shrink phase can dominate wall-clock time. The relevant lever is phases: setting settings(phases=[Phase.explicit, Phase.reuse, Phase.generate]) disables shrinking entirely, which is appropriate for fast smoke runs but produces unreduced reproducers. A safer middle ground is to keep shrinking but cap it: settings(max_examples=50, deadline=None, phases=[Phase.generate, Phase.shrink]) shrinks normally on failure but skips the target phase, which is the slowest contributor on tests that use target(). On a representative suite of 800 property tests with three known failures, dropping the target phase reduced total runtime by roughly 30% and still produced reproducers within one element of the targeted optimum on each failing test.
Radar of Hypothesis Shrinker.
The dashboard view aggregates shrink statistics across that same suite: shrink count per failing test, mean shrink time, and the ratio of valid to invalid attempts. The invalid-attempt ratio is the most useful single number to watch — if it climbs above ~40%, your strategies are leaning on filter or assume too heavily and the shrinker is burning cycles on rejected candidates rather than progress.
Debugging “this shrunk too far”
When the shrunk reproducer looks suspiciously simple — a one-element list where you expected a complex sequence — the usual cause is a separate, unrelated bug that fires earlier. Three levers, in order: add note(repr(state)) inside the test so the printed example carries enough context to disambiguate; add target() on a metric specific to the bug you actually care about (loop iteration count, accumulated state size); and finally label the failure with raise AssertionError("specific bug name") rather than a bare assert, so the Pareto front stores it as a distinct point and Hypothesis won’t merge it with the simpler failure on subsequent runs.
The ECOOP 2020 paper, in three points
MacIver and Donaldson’s ECOOP 2020 paper, Test-Case Reduction via Test-Case Generation: Insights from the Hypothesis Reducer, is the load-bearing reference for everything above. Its three core insights:
- Reducing the choice sequence rather than the generated value means every reduction step yields a valid input by construction, eliminating the entire class of “shrunk to garbage” failures that plague type-directed shrinkers.
- Greedy passes scheduled in a fixed order, applied until a full cycle produces no improvement, are competitive with much more elaborate algorithms while remaining easy to reason about and extend.
- Pareto-front minimization is what makes generic, no-user-intervention reduction safe in the presence of multiple distinct failures: instead of one minimum, you keep an antichain of minima.
The single most effective change you can make to your test suite today: add target() calls anywhere a property fails on a numeric threshold, and stop writing custom shrinkers. The choice-sequence reducer in Hypothesis 6.x is doing more work, more reliably, than any per-type shrinker you would write by hand.
You might also find spillable sink design useful.
If this was helpful, predicate pushdown in lazy engines picks up where this leaves off.
If this was helpful, sub-interpreter isolation model picks up where this leaves off.
References
- HypothesisWorks/hypothesis — conjecture/shrinker.py source
- PR #3962: migrate most shrinker functions to the IR (Liam DeVoe)
- MacIver & Donaldson, “Test-Case Reduction via Test-Case Generation,” ECOOP 2020 (LIPIcs vol. 166, 13:1–13:27)
- David R. MacIver — Compositional shrinking (hypothesis.works)
- DRMacIver/minithesis — single-file reference implementation
- Hypothesis maintainer guide — strategies that shrink well
- Issue #2340: stop shrink phase after timeout when progress is slow


