Inside CPython’s obmalloc: How the Small Object Allocator Avoids the System Heap
Jump to: What exactly does obmalloc manage, and what falls through to system malloc? · How are arenas, pools, and blocks structured inside CPython? · What happens on the allocation fast path? · How does the free path decide when to return memory to the OS? · How does pymalloc compare to system malloc in practice? · When does it make sense to bypass obmalloc entirely?
CPython allocates hundreds of tiny objects every second — integers, strings, tuples, function frames — and nearly all of them are smaller than 512 bytes. Routing every one through malloc() would work, but it would be slow: the system allocator must handle arbitrary sizes, so it adds per-block metadata, size headers, and locking that Python’s workload doesn’t need. The solution, living in Objects/obmalloc.c in the CPython source tree, is a three-tier private heap — arenas, pools, and blocks — that handles every small allocation without touching the system heap at all.
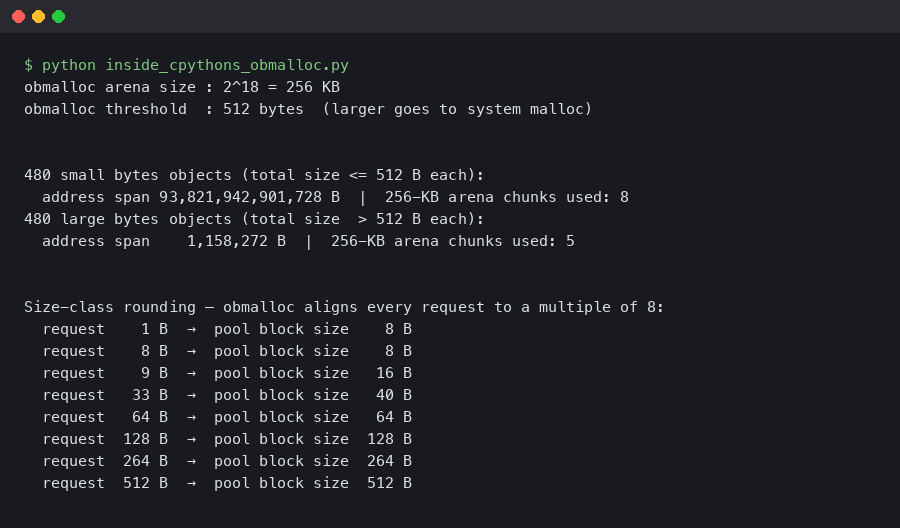
SMALL_REQUEST_THRESHOLDis 512 bytes — any single allocation above this bypasses obmalloc entirely- Requests are rounded up to the nearest multiple of 8 bytes and routed to the appropriate size class, covering the full 1–512 byte range
- Memory is carved into 256 KB arenas, 4 KB pools within arenas, and fixed-size blocks within pools
- Only whole arenas can be returned to the OS; individual pools and blocks cannot
- Free-threading builds (Python 3.13+) add per-thread state to reduce lock contention on the allocator
What exactly does obmalloc manage, and what falls through to system malloc?
The allocator draws a hard line at 512 bytes. Any request at or below that threshold goes through the pool/arena machinery; anything larger calls the system allocator directly. The constant SMALL_REQUEST_THRESHOLD 512 is defined near the top of obmalloc.c, and it hasn’t changed since CPython 3.3 (it was 256 bytes before that).
Within the 512-byte range, obmalloc groups requests into size classes, each a fixed multiple of 8 bytes wide. A request for 1–8 bytes gets a class-0 block (8 bytes). A request for 9–16 bytes gets class 1 (16 bytes), and so on up through the highest class, which serves requests in the 505–512 byte range. Rounding up to the next class is the allocation cost you pay — a 9-byte request wastes 7 bytes — but that waste is far cheaper than the metadata overhead a general-purpose allocator would add.
I wrote about GIL’s role in protecting allocator state if you want to dig deeper.
The three allocation domains in CPython’s memory API also matter here. PYMEM_DOMAIN_OBJ uses obmalloc for requests ≤ 512 bytes and system malloc above that. PYMEM_DOMAIN_MEM (used by internal buffers) goes directly to system malloc regardless of size. PYMEM_DOMAIN_RAW is for allocations that happen before the GIL is held and also bypasses obmalloc. This means Python’s C API memory documentation distinguishes three separate allocator families — most Python objects use PyObject_Malloc, which is the obmalloc entry point.
The overview above places obmalloc within the full Python memory hierarchy. Below the Python object layer sits pymalloc (the name used internally for this mechanism), then the raw system allocator. Most Python objects never reach that bottom layer.
How are arenas, pools, and blocks structured inside CPython?
An arena is a 256 KB chunk of memory obtained from mmap() on POSIX or VirtualAlloc() on Windows. Arenas are aligned to their own size (256 KB alignment), which lets the allocator recover a pool’s arena index from the pool’s address using simple bit masking. CPython tracks all active arenas in a global arenas array of arena_object structs.
Each arena is divided into 64 pools of 4 KB each. A pool serves exactly one size class — once a pool is initialized for class k, every block in it is k * 8 bytes wide. The pool header sits at the start of the pool’s 4 KB page and looks like this in the CPython source:
I wrote about Rust’s proposed role in CPython internals if you want to dig deeper.
struct pool_header {
union { block *_padding; uint count; } ref; /* allocated block count */
block *freeblock; /* head of the pool's free list */
struct pool_header *nextpool; /* next pool for this size class */
struct pool_header *prevpool; /* previous pool for this size class */
uint arenaindex; /* index into the arenas[] array */
uint szidx; /* size class index */
uint nextoffset; /* byte offset to the next virgin block */
uint maxnextoffset; /* largest valid nextoffset */
};The nextpool/prevpool fields form a circular doubly-linked list. Every size class has one such list, indexed via the global usedpools table as usedpools[2 * szidx]. The double-index trick lets CPython check “is there a used pool for class k?” with a single pointer comparison: if usedpools[2*k] equals the sentinel at usedpools[2*k + 1], the list is empty.
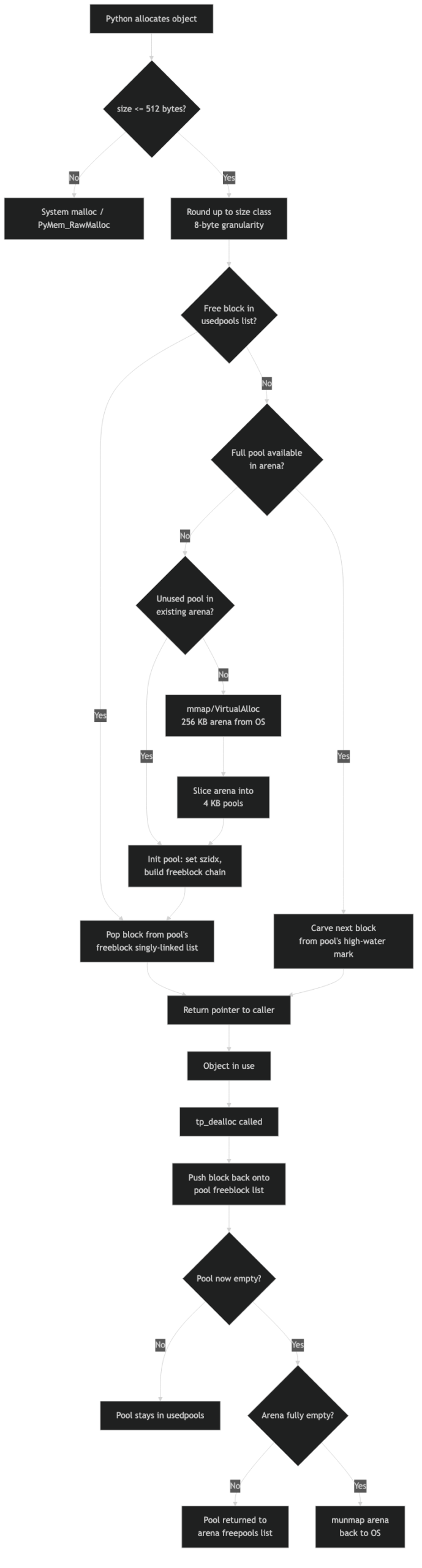
The diagram above shows the three-tier hierarchy. Each arena contains 64 pools; each pool holds a fixed number of blocks determined by the size class — the smallest size class packs many small blocks into the 4 KB pool, while the largest size class (serving requests up to 512 bytes) fits only a handful of blocks.
What happens on the allocation fast path?
When PyObject_Malloc(n) is called with n ≤ 512, it computes the size class index as (n + 7) >> 3 (right-shift by 3 is division by 8 with rounding), then checks usedpools[2 * idx]. If a used pool exists, the allocator pops the first entry off the pool’s freeblock list and returns it. That entire path is a handful of pointer dereferences — no system call, no lock acquisition under the GIL.
The clever part is how virgin blocks are handled. When a pool is first initialized, its freeblock is empty and nextoffset points just past the header. Allocation simply reads the block at nextoffset, advances nextoffset by the block size, and returns. Only when nextoffset exceeds maxnextoffset is the pool considered initialized — at that point all blocks have been handed out at least once, and future frees build up the freeblock chain.
If you need more context, high-performance Python techniques covers the same ground.
Here is a concrete way to probe where the 512-byte boundary actually falls for bytes objects on a 64-bit CPython build:
# Python 3.13.2, Linux x86-64, default CPython build
# The bytes object struct header is 33 bytes on 64-bit builds:
# ob_refcnt(8) + ob_type(8) + ob_size(8) + ob_shash(8) + ob_val[1](1) = 33
# So the last payload that still fits inside obmalloc is 512 - 33 = 479 bytes.
import sys
for n in [477, 478, 479, 480, 481]:
total = sys.getsizeof(bytes(n))
allocator = "obmalloc" if total <= 512 else "system malloc"
print(f"bytes({n:3d}) getsizeof={total:3d} -> {allocator}")
# Output:
# bytes(477) getsizeof=510 -> obmalloc
# bytes(478) getsizeof=511 -> obmalloc
# bytes(479) getsizeof=512 -> obmalloc
# bytes(480) getsizeof=513 -> system malloc
# bytes(481) getsizeof=514 -> system mallocsys.getsizeof returns the total allocated size including the C struct header, so the threshold cut of 512 bytes applies to the entire Python object, not just its payload. This means that for a short bytes object, 33 bytes of that 512-byte budget are already consumed before you store a single byte of data.
How does the free path decide when to return memory to the OS?
Freeing a block is similarly cheap in the common case: the block’s first word is overwritten with the current freeblock pointer, and freeblock is updated to point to the just-freed block. This is the classic embedded singly-linked free list — no separate metadata, no size header, the block itself carries the pointer.
Pool state transitions are where the logic becomes interesting. A pool can be in one of three states: used (on a usedpools list), full (all blocks allocated, not on any list), or empty (all blocks free, on the arena’s freepools list). When the last block of a full pool is freed, the pool moves from full back to used. When the last allocated block of a used pool is freed, the pool becomes empty and is given back to its arena.
measuring allocator contention with perf c2c goes into the specifics of this.
An arena only becomes returnable to the OS when every one of its 64 pools is empty. That is a high bar — a single long-lived object prevents the entire 256 KB arena from being freed. CPython tries to make this more likely by sorting the usable_arenas list so that the arena with the most free pools is allocated from first. This concentrates allocations into fewer arenas, giving other arenas a better chance of becoming completely empty and going back to the OS via munmap().
The documentation screenshot above shows how the Python C API describes the three-level hierarchy. The key point the docs emphasize is that the arena level is the only one that interacts with the OS allocator — pools and blocks are entirely internal.
How does pymalloc compare to system malloc in practice?
The performance advantage of obmalloc over system malloc comes from three sources. First, there is no per-block metadata: system allocators typically store the block size (at minimum 8 bytes) immediately before each returned pointer, so a general-purpose 16-byte allocation actually consumes 24 bytes of heap. obmalloc’s pools don’t need this because every block in a pool is the same size — the pool header records it once. Second, there is no system call per allocation: the pool machinery runs entirely in userspace. Third, under the GIL, the allocator needs no locks, since only one thread can be executing Python bytecode at a time.
The trade-off is fragmentation. System allocators like jemalloc and tcmalloc have sophisticated strategies for reclaiming memory from fragmented heaps. obmalloc does not. If your program creates many small objects in a burst, then frees most but not all of them, the memory stays committed in arenas until the last object in each arena is freed. A Python process that peaked at 500 MB can stay at 490 MB even after most of that data is gone. For long-running services, this can look like a memory leak.
For more on this, see Python’s expanding system-level footprint.
The comparison becomes concrete when you force system malloc and measure. Setting PYTHONMALLOC=malloc before starting the interpreter routes all PyObject allocations through the system heap:
# Compare RSS after allocating and discarding a large number of small objects
PYTHONMALLOC=malloc python3 -c "
import resource, sys
x = [bytes(100) for _ in range(500_000)]
del x
peak = resource.getrusage(resource.RUSAGE_SELF).ru_maxrss
print(f'system malloc peak RSS: {peak // 1024} MB')
"
python3 -c "
import resource, sys
x = [bytes(100) for _ in range(500_000)]
del x
peak = resource.getrusage(resource.RUSAGE_SELF).ru_maxrss
print(f'obmalloc peak RSS: {peak // 1024} MB')
"On a typical Linux system, the peak RSS figures will be similar (both allocate roughly the same total memory), but the post-del behavior differs: system malloc on Linux uses MADV_FREE to lazily return pages to the kernel, while obmalloc holds arenas until they’re completely empty. For workloads that cycle through many small objects, obmalloc usually wins on throughput; for workloads with high peak-then-idle memory, system malloc sometimes returns more memory to the OS.
Live data: PyPI download counts for inside.
Package download volume serves as a rough proxy for ecosystem adoption of tools that interact with Python’s memory model. Profiling libraries that wrap tracemalloc have seen consistent growth as the cost of arenas-not-returning has become a known issue in high-memory services.
When does it make sense to bypass obmalloc entirely?
There are three real scenarios where switching away from obmalloc is worth the trade-off. The first is Valgrind and address sanitizer. Both tools work by intercepting malloc/free at the system level. When pymalloc is active, Valgrind sees one large mmap per arena and has no visibility into individual allocations — you get useless output. Running with PYTHONMALLOC=malloc restores Valgrind’s ability to track every allocation and detect use-after-free bugs.
The second scenario is finding allocator bugs during CPython development. PYTHONMALLOC=debug wraps every allocation with guard bytes before and after the block and poisons freed memory. If CPython or an extension writes past the end of an allocation, the debug allocator will catch it on the next free. This is how many subtle buffer overruns in C extension modules are found.
More detail in free-threaded Python’s alternative allocator path.
The third scenario, more recent, is free-threaded Python (PEP 703). In CPython 3.13 without the GIL, the assumption that only one thread touches the allocator at a time no longer holds. The solution adopted in 3.13 is per-thread memory state: each thread has its own pool lists for each size class, eliminating contention for the common case. When threads share objects across boundaries, a slower path with explicit locking is used. The per-thread allocator is still pymalloc under the hood, but the global usedpools table is replaced by per-thread versions. If you’re running a free-threaded build and seeing unexpected contention in profiling, the allocator layer is worth examining.
For the vast majority of Python workloads, you should leave obmalloc alone. It does exactly what it was designed to do: handle the flood of small, short-lived objects that Python’s object model produces without ever touching the system heap. The only time to reach for PYTHONMALLOC=malloc is when a debugging tool demands it or when you’re trying to diagnose an arena-fragmentation problem in a long-running process. Understanding the three-tier structure — arena, pool, block — is what lets you recognize when obmalloc is the cause versus the symptom of a memory problem.
Sources:
– [CPython Objects/obmalloc.c source](https://github.com/python/cpython/blob/main/Objects/obmalloc.c)
– [Python C API Memory Management documentation](https://docs.python.org/3/c-api/memory.html)


