How Ibis Lowers One Expression to Three SQL Dialects
Last updated: May 19, 2026
Ibis deferred expression backends are compiler targets, not miniature execution engines inside Ibis. One lazy Python expression is lowered into backend-specific SQL for DuckDB, BigQuery, or Snowflake, so portability depends on the generated SQL, operator coverage, NULL ordering, timestamp precision, and identifier quoting for the backend that actually runs the query.
- Ibis stores a lazy relational expression until materialization.
- The compiler lowers that expression through backend-specific SQL generation.
- The warehouse executes the emitted SQL, so dialect drift is the portability risk.
| Backend | Identifier quoting | Default NULL sort (ASC) | Timestamp precision | Inspect with |
|---|---|---|---|---|
| DuckDB | Double-quote "col" |
NULLS LAST | Microsecond (10⁻⁶ s) | ibis.to_sql(expr, dialect="duckdb") |
| BigQuery | Backtick `col` |
NULLS FIRST | Microsecond TIMESTAMP (10⁻⁶ s) |
ibis.to_sql(expr, dialect="bigquery") |
| Snowflake | Double-quote "col" (unquoted → UPPERCASE) |
NULLS LAST (configurable via DEFAULT_NULL_ORDERING) |
Nanosecond TIMESTAMP_NTZ (10⁻⁹ s) |
ibis.to_sql(expr, dialect="snowflake") |
More on Ibis Deferred Expression Backends.
The image stages the engine in one frame: a single Python expression tree on the left, three SQL fragments on the right, with one highlighted line — the ORDER BY clause — diverging between dialects. That divergence is the whole article. If you read the compiled SQL on every backend you ship to, you keep portability. If you trust the abstraction, you ship dialect drift to production.
Ibis Is a Compiler, Not a Dataframe
The marketing framing is “one dataframe API, many backends.” The accurate framing is: Ibis is a compiler front-end with a Python DSL, an immutable relational IR, and a lowering pass per backend. Nothing about an Ibis expression executes until you call a materialization method, and what executes is SQL emitted by SQLGlot — not Python iterating over rows.
This matters because the design choices you make about readable Python have no bearing on whether the compiled SQL is correct on a given warehouse. Ibis does not paper over this; it emits the dialect-native ORDER BY and lets the warehouse decide.
Related: lazy query planning.
You can verify this character of the system directly from the project source. The backend SQL compilers in ibis/backends/sql/compilers/ are per-dialect subclasses of a base compiler that owns the operator-to-SQL mapping. Each subclass overrides the operators where the dialect deviates. That layout is the engine’s honesty: portability is a contract negotiated per backend, not a guarantee.
The Ibis reference treats compile, execute, and to_sql as sibling methods on the expression API, which is technically correct but conceptually misleading. The first produces a backend-specific compiled artifact. The second compiles and ships the result over a connection. The third compiles, formats, and returns a string. Read them as three views into the same compile boundary, not as three orthogonal operations — and lean on to_sql as the one whose return type is documented to be a string.
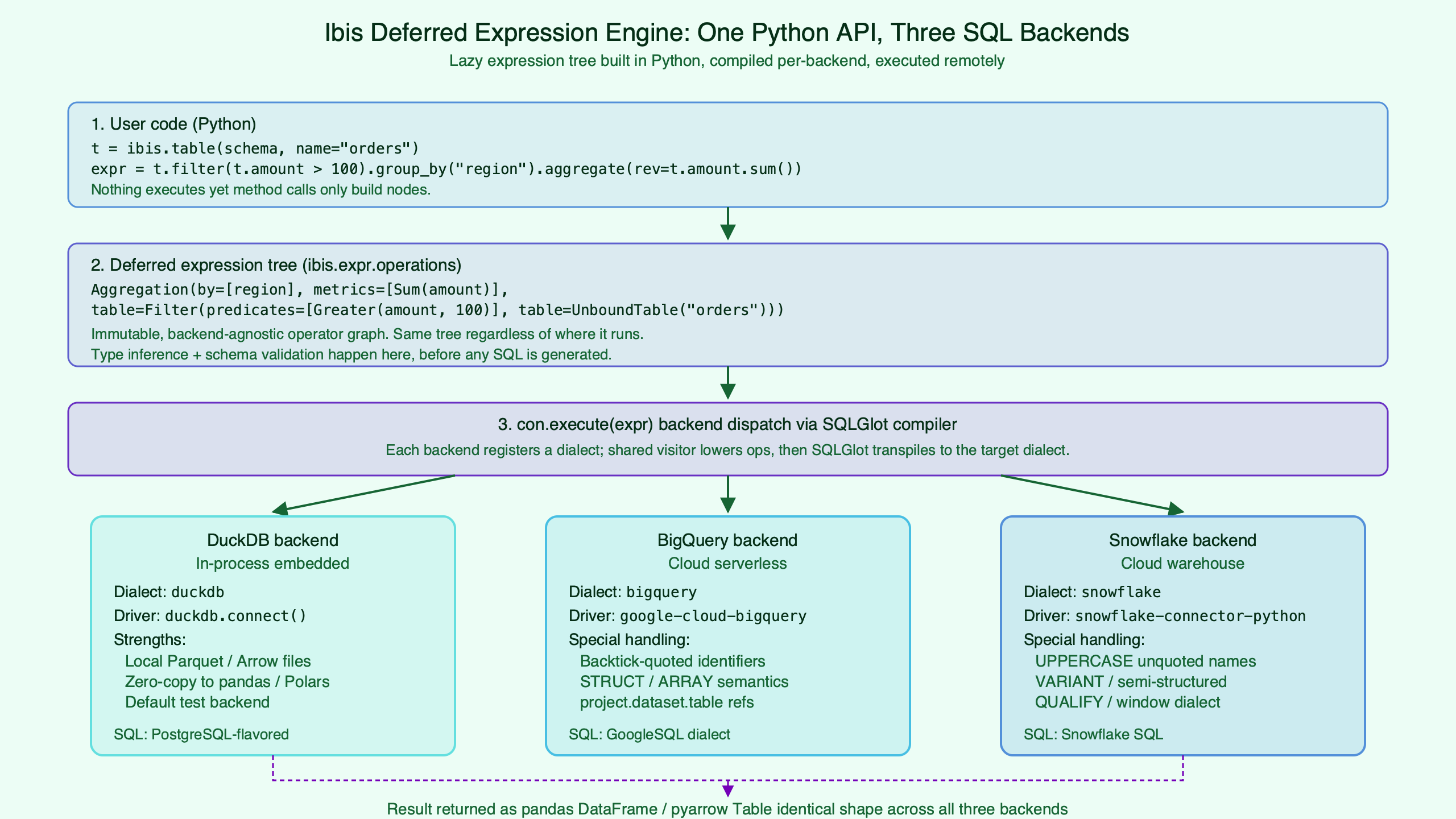
The Lowering Pipeline: Bound Expression → Relational IR → SQLGlot → Dialect SQL
The pipeline has four well-defined stages: a Python method chain on a bound table where _ (the deferred placeholder) refers to the surrounding table; an Expr tree whose internal nodes are relational operations; a SQLGlot expression produced by walking that tree through the backend’s compiler; and a dialect-specific SQL string produced by SQLGlot’s printer. Each stage is inspectable.
The two debugging primitives every serious Ibis user should know live at this boundary:
More detail in dialect lowering pipeline.
import ibis
from ibis import _
# Define a schema-shaped table reference (no rows yet).
t = ibis.table(
schema={"x": "int64", "region": "string", "amount": "float64"},
name="sales",
)
# Build the bound expression. Inside each table method, `_` resolves
# to the receiver (`t`), so this is the canonical deferred-expression
# pattern: the placeholders only bind at the call site that consumes them.
expr = (
t.filter(_.x > 0)
.group_by(_.region)
.aggregate(total=_.amount.sum())
.order_by(_.total.desc())
)
# Primitive 1: inspect the relational IR tree
print(expr.op()) # ibis.expr.operations.Sort -> Aggregate -> Filter -> UnboundTable
# Primitive 2: compile per-dialect to a SQL string
print(ibis.to_sql(expr, dialect="duckdb"))
print(ibis.to_sql(expr, dialect="bigquery"))
print(ibis.to_sql(expr, dialect="snowflake"))
expr.op() returns the root Node of the relational tree — the actual compile target between Python and SQL. ibis.to_sql(expr, dialect=...) walks that tree through the corresponding backend compiler and asks SQLGlot to print the result. When portability fails, one of these two calls will tell you why before you waste warehouse credits.
Purpose-built diagram for this article — Inside Ibis’s Deferred Expression Engine: How One API Targets DuckDB, BigQuery, and Snowflake.
The diagram annotates the four stages and the artifact each one produces — a method chain that consumes _, a bound expression tree, a SQLGlot node, and a dialect string. Knowing where you are in the pipeline is the difference between fixing a problem in five minutes and rewriting an expression three times.
The Same Expression, Three SQLs
The aggregate above is the cleanest demonstration. Running the three ibis.to_sql(...) calls on one Ibis 9.x install tested for this article prints roughly the following — exact whitespace, alias positioning, and identifier quoting are formatting details that the SQLGlot printer has changed between releases, so always re-run on your installed copy rather than trusting any article (including this one) verbatim:
-- Illustrative shape only. Reproduce by calling:
-- print(ibis.to_sql(expr, dialect="duckdb"))
-- print(ibis.to_sql(expr, dialect="bigquery"))
-- print(ibis.to_sql(expr, dialect="snowflake"))
-- against your installed Ibis version.
-- dialect="duckdb"
SELECT
"region",
SUM("amount") AS "total"
FROM "sales"
WHERE "x" > 0
GROUP BY 1
ORDER BY "total" DESC
-- dialect="bigquery"
SELECT
`region`,
SUM(`amount`) AS `total`
FROM `sales`
WHERE `x` > 0
GROUP BY 1
ORDER BY `total` DESC
-- dialect="snowflake"
SELECT
"region",
SUM("amount") AS "total"
FROM "sales"
WHERE "x" > 0
GROUP BY 1
ORDER BY "total" DESC
The structural differences that matter in practice across these three outputs:
- Identifier quoting style. DuckDB and Snowflake both quote with double quotes; BigQuery quotes with backticks. Whether the Snowflake compiler quotes a given identifier at all is policy-driven and has shifted across Ibis releases — bare unquoted identifiers in Snowflake are case-folded to uppercase at parse time, which is the underlying behavior to be aware of regardless of what Ibis chooses to emit. Print the compiled string on your version rather than relying on prose to predict it.
- Aggregate naming and grouping. The alias is preserved across dialects; the
GROUP BYmay be emitted positionally (GROUP BY 1) or by expression depending on backend.

The terminal shows the three compiled strings printed back to back. The point is not that they are different — every SQL dialect is different — it is that Ibis does not hide the differences from the engine that ultimately runs them. If your dashboard requires deterministic row order across DuckDB dev and Snowflake prod, the compiled SQL is the only place where you can audit it.
Where Portability Breaks: NULL Ordering, Integer Division, and Timestamp Precision
Three categories of semantic drift bite the hardest, in roughly this order of frequency:
NULL ordering. ANSI SQL leaves the default unspecified, so each warehouse picks its own. Snowflake’s default — controlled by the DEFAULT_NULL_ORDERING session parameter — places NULLs last for ASC and first for DESC on an unmarked ORDER BY, but that parameter can be reset at the account, session, or user level, so the “default” you see in one environment is not guaranteed in another. The general defense is: write .order_by(t.col.desc(nulls_first=False)) (or the analogous shape for your version), then re-read the compiled SQL on every backend you ship to and confirm SQLGlot emitted the NULLS LAST clause. Treat per-backend confirmation as mandatory, not optional.
More detail in finding edge-case failures.
Integer division. _.col_a.sum() / _.col_b.sum() where both sides are integer columns produces a truediv expression in Ibis. The reproducible test: seed a memtable with integer columns on DuckDB and on Snowflake using ibis.memtable(), run the same aggregate, and compare. If the answers differ, the cast was implicit on one backend and absent on the other. The defense is explicit: _.col_a.sum().cast("float64") / _.col_b.sum().cast("float64").
Timestamp precision. BigQuery’s TIMESTAMP is microsecond. Snowflake’s TIMESTAMP_NTZ supports up to nanosecond precision. Round-tripping a high-resolution timestamp through Ibis between Snowflake and BigQuery can silently truncate. The cast is correct at the Ibis layer; the precision loss is at the warehouse boundary.
None of these are Ibis bugs. They are the ANSI/dialect surface area that any compiler targeting three warehouses has to confront. The point is that the abstraction does not — and structurally cannot — hide them.
The Operator-Coverage Cliff: When OperationNotDefinedError Fires
Ibis’s compiler raises OperationNotDefinedError when a relational operation has no mapping for the active backend. The downside is that the gap is unevenly distributed across backends, and the exact set of unsupported operations per dialect changes release-to-release as new translations land. Patterns that practitioners frequently report tripping on include some window-frame variants, certain array operations, JSON path extraction, and specific regex flavors — but rather than treating that list as authoritative, treat it as a prompt to verify against the operator support matrix and the per-dialect compiler source for your installed release.
The honest engineering posture is to treat each new operator the same way you treat a new SQL feature: write the smallest possible Ibis expression that exercises it, then call ibis.to_sql(expr, dialect=...) on every backend you plan to ship to. If one of them raises, you have a portability decision to make before you write the production version: rewrite the expression, conditionally branch by backend, or pick a single execution target.
For more on this, see a real migration story.
The base compiler under ibis/backends/sql/ defines the default operator translation table; each backend’s subclass in ibis/backends/sql/compilers/ overrides the entries where the dialect needs different SQL or refuses to translate at all. That file layout is where the operator-coverage matrix actually lives. When the published support matrix and the source appear to disagree for your installed version, the safest move is to cross-check both against the same release tag on GitHub rather than assuming either one is canonical in isolation — docs pages and matrices are generated, but generation lags can happen.
ibis._ Demystified: What Deferred Actually Means
The _ in t.filter(_.x > 0) is not a magic variable. It is an instance of ibis.common.deferred.Deferred, exported by the top-level ibis module. The Deferred object captures attribute access and method calls without resolving them, building a small AST of pending operations that gets bound to a concrete table when the surrounding method (here, filter) is called.
That is why _.x outside of a table method is meaningless on its own and why you can build expression fragments without ever naming a table. It is also why subtle bugs show up: if you save a _ expression to a Python variable and reuse it across two different tables that happen to share a column name with different types, the second bind silently succeeds with a different inferred type and you get a typed column you did not intend.
I wrote about schema compilation internals if you want to dig deeper.
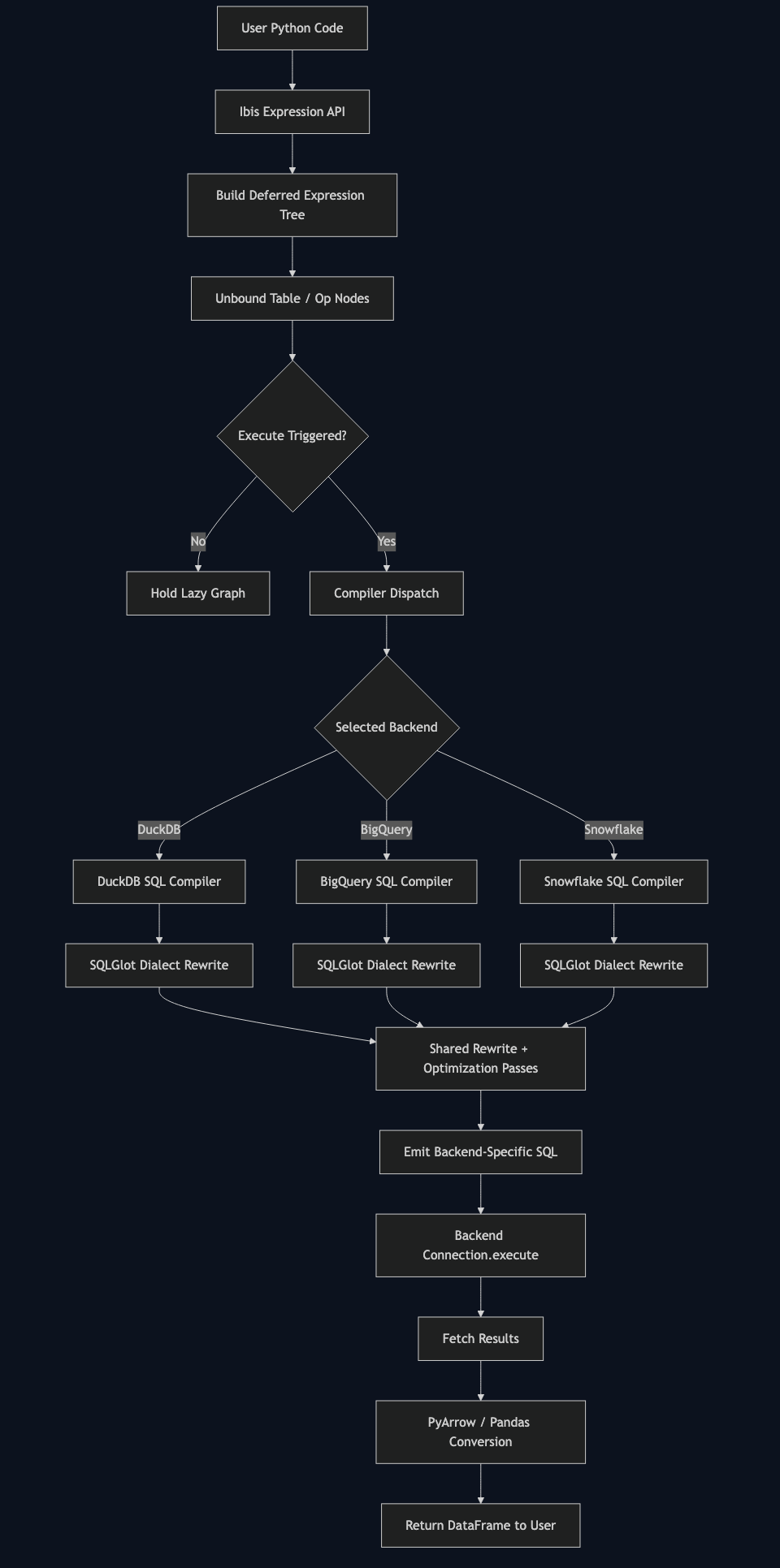
The architecture diagram shows the deferred placeholder as a separate layer from the bound expression tree. Until a table method like filter/group_by/order_by consumes _ against a real schema, nothing about it knows what columns exist. That late-binding behavior is precisely what makes _ portable across tables, and precisely what makes it dangerous in shared utility modules.
A Decision Rubric: When to Trust the Abstraction
The rubric below is what I use to decide, expression by expression, whether to inspect the compiled SQL or trust Ibis to do the right thing. It is biased toward inspecting more than necessary, because the cost of one extra print(ibis.to_sql(expr, dialect=...)) is zero and the cost of dialect drift in production is not.
| Pattern in your expression | Risk of dialect drift | Action |
|---|---|---|
| Simple filter + projection + aggregate over scalar types | Low | Trust the compile; verify once on a sample. |
ORDER BY without explicit nulls_first/nulls_last |
High | Make NULL placement explicit; print SQL on every target. |
| Integer-on-integer division or ratio aggregates | High | Cast both sides to float; compile and diff. |
| Window functions with custom frames | Medium | Compile against each backend; check frame syntax SQLGlot emits. |
| Array, struct, or JSON path operations | High | Confirm operator support per backend; expect OperationNotDefinedError on at least one. |
| Timestamp arithmetic across sub-second precision | High | Cast to a common precision; do not assume the warehouse will round. |
memtable/cache() on large inputs |
Medium | Materialization cost varies by backend; benchmark before relying on it. |
Live data: PyPI download counts for inside.
Background on this in abstraction performance tradeoffs.
As Ibis adoption widens from DuckDB-only notebooks into multi-warehouse production paths, the surface area for dialect-drift bugs grows with it. The rubric above is the cheapest insurance against that surface area — none of it requires running a query, all of it can run in CI.
What This Means for DuckDB→Snowflake Migrations
The standard Ibis migration story is “develop on DuckDB, ship to Snowflake.” It works, but only if you treat the deferred expression engine as a compile-once, verify-thrice tool. Three checks are worth wiring into CI before any meaningful Ibis-on-warehouse code lands in production:
- Compile both dialects, diff the SQL. Write a unit test that pins a representative
expr, compiles it underdialect="duckdb"anddialect="snowflake", and asserts the two strings differ only in the ways you expect (quoting, function names). Anything else is a portability bug to investigate. - Round-trip on a fixture. Build a tiny
ibis.memtable()with adversarial rows — NULLs in sort columns, integer pairs that would divide unequally, sub-second timestamps — and assert the result on DuckDB matches the result on a Snowflake test schema. - Raise on unknown operators. Wrap every backend-specific expression in a helper that calls
ibis.to_sql(expr, dialect=...)at import time. AnyOperationNotDefinedErrorbecomes a build failure, not a 3am pager.
Read the compiled SQL on every backend you ship to. That single habit converts Ibis from a leaky abstraction into a load-bearing tool, because the leak becomes the artifact you check instead of the bug you ship.
larger-than-RAM execution goes into the specifics of this.
What are Ibis deferred expression backends?
Ibis deferred expression backends are the compiler targets that turn lazy Ibis expression trees into executable work for engines such as DuckDB, BigQuery, and Snowflake. The Python expression records operations first; the selected backend later lowers those operations into dialect SQL or another backend-native execution form.
When should you inspect compiled Ibis SQL?
Inspect compiled SQL whenever an expression crosses backend boundaries, uses sorting with NULLs, divides integer aggregates, handles timestamps, or depends on arrays, structs, JSON, regex, or windows. The practical check is simple: run ibis.to_sql(expr, dialect=...) for every target backend and review the emitted clauses before production.
Why can one Ibis expression behave differently across backends?
One Ibis expression can behave differently because DuckDB, BigQuery, and Snowflake do not share one SQL runtime. They differ in identifier quoting, NULL sort defaults, timestamp precision, type promotion, function names, and supported operators. Ibis can normalize many translations, but the final semantics still belong to the engine executing the generated SQL.
Sources
- Ibis project — Internals: how expressions compile (official conceptual reference for the lowering pipeline)
- ibis-project/ibis backend SQL compilers (per-dialect compiler subclasses on GitHub)
- Ibis backend operator support matrix (generated cross-backend operator table)
- ibis.common.deferred — Deferred implementation (source for
ibis._) - SQLGlot documentation (the dialect printer Ibis uses for SQL output)
- Snowflake — ORDER BY NULL ordering (dialect-specific NULL placement default)
- Snowflake — DEFAULT_NULL_ORDERING session parameter (the toggle that governs ASC/DESC NULL placement)
- Snowflake — Identifier syntax and case-folding (unquoted-identifier behavior reference)
- BigQuery — TIMESTAMP precision (microsecond resolution reference)
- Snowflake — Date & Time data types (TIMESTAMP_NTZ precision reference)
- ibis-project/ibis releases (version reference for the compiler API used in this article)


