
Inside Pydantic v2’s Core: How pydantic-core Compiles Schemas to
Last updated: May 08, 2026
Pydantic-core compiles your models by walking a Python-emitted CoreSchema dict — a tagged-union intermediate representation — once at construction time and building a tree of Rust enum variants (a CombinedValidator) inside a single SchemaValidator; every later validate_python call dispatches through that pre-built tree. This is not codegen: no per-model Rust source, no machine code emitted for your annotations, no AOT step. Pydantic-core is an interpreter over a Python-supplied IR, which is why issue #402‘s “generate a Rust struct per model” framing misses the design. The expensive work runs once at class-creation time (or first validation, if defer_build=True), so import-time regressions and custom-validator slowdowns trace to that one-time IR walk — not to the hot validate path, a PGO-tuned tagged-union dispatch that stays fast.
What we cover:
- Pydantic-core is an interpreter, not a code generator
- The CoreSchema IR: the dict pydantic-core actually consumes
- SchemaValidator::new — what “compilation” really means here
- Why pydantic-core does not codegen Rust per model — and why issue #402 is misframed
- The three-phase cost model: class body, SchemaValidator construction, validate_python
- Custom validators and the PyO3 callback boundary
- Recursive models, definitions, and refs
- What PGO and the release profile buy a tagged-enum interpreter
- The mental model to keep
- References
- pydantic core schema compilation is
SchemaValidator::newwalking a CoreSchema dict once and building aCombinedValidatorenum tree — no per-model Rust codegen. - Each
BaseModelsubclass triggers schema generation and validator construction at class-creation time, even when used only as a nested field. - pydantic-core wheels are built with
profile=release pgo=true(printed bypydantic.version.version_info()). defer_build=Truepostpones the IR walk to first validation; it does not remove it.
Pydantic-core is an interpreter, not a code generator
The headline claim of pydantic v2 — “validation rewritten in Rust” — is true, but the popular mental model is wrong. There is no per-model Rust function. There is no monomorphic struct generated from your type hints. The Rust side never sees your annotations at all. What it receives is a JSON-serializable Python dict with a recursive shape, dispatched by a type tag at every node. Construction is the moment the dict turns into a tree of Rust enum variants; validation is dispatch through that tree.
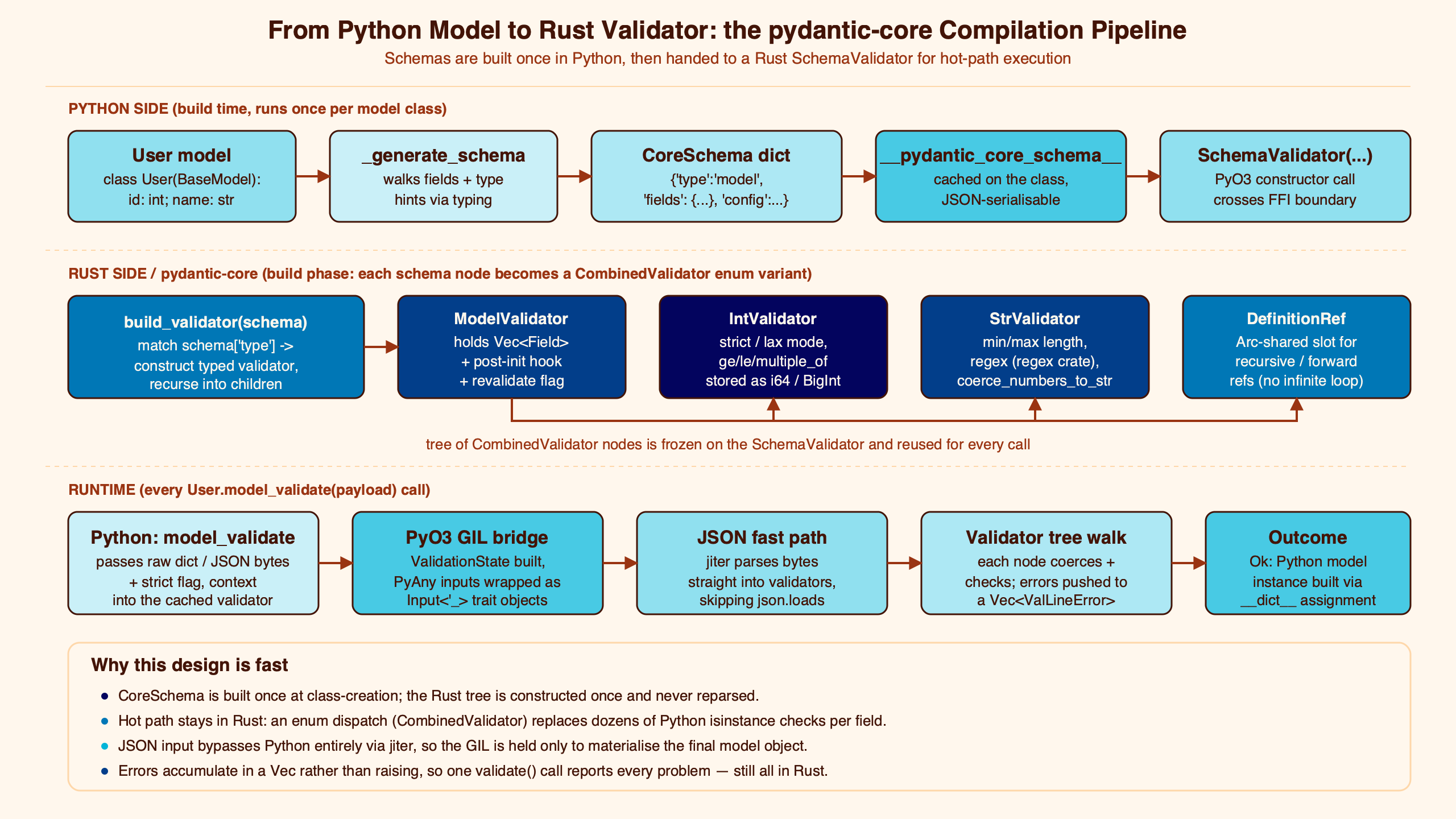
Purpose-built diagram for this article — Inside Pydantic v2’s Core: How pydantic-core Compiles Schemas to Rust Validators.
A related write-up: how MLIR lowers Python.
The diagram above traces the path from a Python class body through _generate_schema, into the CoreSchema dict, across the PyO3 boundary, and into the CombinedValidator tree that lives inside a SchemaValidator. Two arrows are worth pausing on: the one from Python to Rust carries a dict, not type hints, and the one inside Rust is built once per class, not once per validate call.
This framing matters because pydantic-core’s whole performance story sits on it. The fast path is dispatch through a tagged union of pre-built validators inside one process; the slow path is the IR walk that builds them. Mistaking those two phases for one is the single biggest source of confusion in the public conversation about v2 perf.
The CoreSchema IR: the dict pydantic-core actually consumes
Every BaseModel subclass exposes __pydantic_core_schema__, the exact dict pydantic-core consumes. Print it for a three-field model and the structure becomes obvious.
from pydantic import BaseModel
from pprint import pprint
class M(BaseModel):
x: int
y: str
z: list[int]
pprint(M.__pydantic_core_schema__, depth=4)
# {'type': 'model',
# 'cls': <class '__main__.M'>,
# 'schema': {'type': 'model-fields',
# 'fields': {'x': {'type': 'model-field',
# 'schema': {'type': 'int'}},
# 'y': {'type': 'model-field',
# 'schema': {'type': 'str'}},
# 'z': {'type': 'model-field',
# 'schema': {'type': 'list',
# 'items_schema': {'type': 'int'}}}},
# 'model_name': 'M'},
# 'ref': '__main__.M:...',
# 'config': {'title': 'M'},
# 'custom_init': False,
# 'root_model': False}
That terminal capture is the IR pydantic-core actually receives — a recursive Python dict where every node carries a type string (“model”, “model-fields”, “model-field”, “int”, “str”, “list”). The items_schema key on the list node is itself a CoreSchema, and the same recursion holds for unions, dicts, dataclasses, typed-dicts, and function validators. The full tag set spans primitives (“any”, “none”, “bool”, “int”, “float”, “str”, “bytes”), temporals (“date”, “time”, “datetime”, “timedelta”), collections (“list”, “tuple”, “set”, “frozenset”, “dict”), composites (“union”, “tagged-union”, “chain”), structurals (“model”, “model-fields”, “typed-dict”, “dataclass”), and utilities (“function-before”, “function-after”, “function-wrap”, “definitions”, “definition-ref”, “with-default”, “nullable”). The pydantic_core.core_schema reference lists every TypedDict.
There is a longer treatment in small-object allocator design.
The reason this matters is the boundary it draws. The Rust side has zero knowledge of typing, generics, or your annotations. Anything pydantic chooses to support — every type adapter, every custom serializer hook, every __get_pydantic_core_schema__ override — eventually reduces to one of those tag values. The IR is the contract.
SchemaValidator::new — what “compilation” really means here
The word “compile” gets used loosely around pydantic v2. The precise event is this: when Python instantiates SchemaValidator(core_schema), the Rust constructor walks the CoreSchema dict once, top-down, and builds a tree of CombinedValidator enum variants. Each tag becomes a variant: 'int' becomes CombinedValidator::Int(IntValidator { ... }), 'list' becomes CombinedValidator::List(ListValidator { item_validator: Box<CombinedValidator> }), and so on. The result is a recursive enum tree owned by the SchemaValidator Python object.
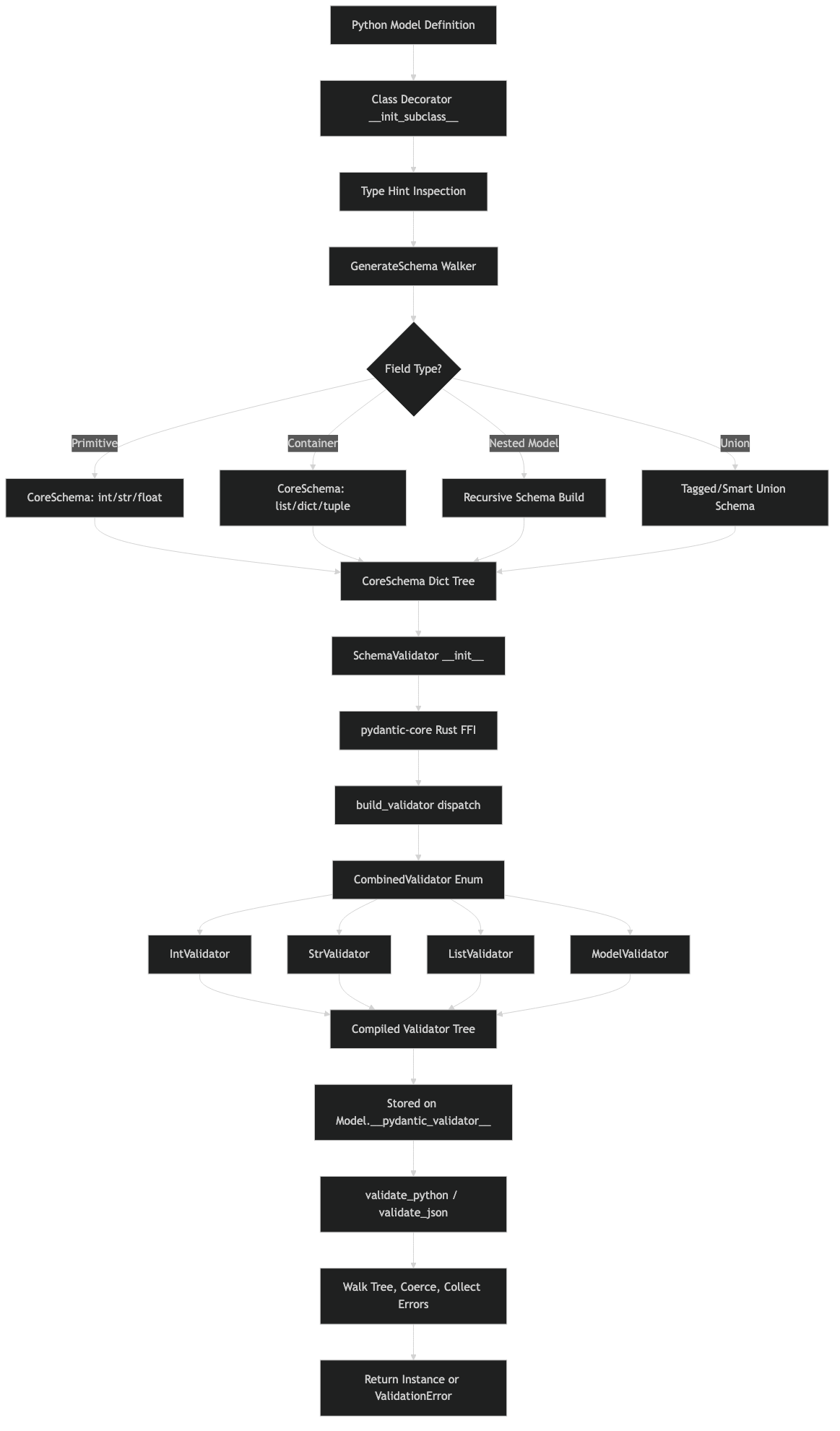
The architecture diagram makes the layering visible. Python sits above the FFI boundary; the SchemaValidator Python wrapper holds a single owned CombinedValidator; that enum, at every variant, may contain more boxed CombinedValidator children. The construction-time pass is the only place where the Python dict is read at all. After it returns, the dict is no longer needed and the validator tree is the only object dispatch traverses on each validate call.
Reading pydantic-core’s own architecture page makes the split explicit: pydantic and pydantic-core are “two distinct packages”, communicating exclusively through the CoreSchema dict, with the Rust layer providing SchemaValidator and SchemaSerializer. Once that boundary is drawn, “schema compilation” stops being a vague performance term and starts being a concrete, measurable event with one entry point.
Why pydantic-core does not codegen Rust per model — and why issue #402 is misframed
The most cited proposal in this corner of the SERP is pydantic-core issue #402, “Generate and compile Rust struct for Pydantic model at runtime and ahead of time.” The premise is that pydantic-core could be made faster by generating a real Rust struct per model and compiling it. The framing treats schema compilation as an unimplemented dream. It is not unimplemented; it is implemented differently.
What pydantic-core actually does is the interpreter trade-off. A tagged-union enum dispatch over CombinedValidator is not free per call — it pays a match cost — but it amortizes the construction work across every validate call and ships as a single shared library. Codegen would replace the match with a direct call, but it would also require either (a) shipping a Rust toolchain to every user and rebuilding on import, or (b) standing up an AOT pipeline keyed on every distinct model in every codebase. The interpreter design eats a small per-call dispatch cost to avoid both.
I wrote about Rust inside CPython if you want to dig deeper.
This is the same trade-off you see in regex engines (compiled NFA interpreted vs. JIT), in JSON parsers (table-driven vs. specialized), and in protobuf (reflection vs. generated code). Pydantic-core sits at the interpreter end of that spectrum, deliberately. The competitor framing — “v2 isn’t fast because it doesn’t codegen yet” — confuses the architecture pydantic-core shipped with one it explicitly chose not to ship.
The three-phase cost model: class body, SchemaValidator construction, validate_python
Most reports of “pydantic v2 is slower than I expected” collapse three different phases into one number. Separate them and the picture changes.
Phase 1 — class body execution and schema generation. Every class M(BaseModel): triggers Python-side _generate_schema walking your annotations and emitting a CoreSchema dict. This is pure Python, runs at import time, and scales with the number of fields and the depth of nested models.
Background on this in property-based test minimization.
Phase 2 — SchemaValidator::new. The Rust-side IR walk that produces the CombinedValidator tree. Also import-time, also paid once per class, but it crosses the PyO3 boundary and traverses the dict.
Phase 3 — validate_python. The hot path. Per-instance dispatch through the pre-built validator tree. This is the path that the Rust binary’s profile=release pgo=true build is tuned for; the import-time phases barely benefit from PGO at all because they run once.
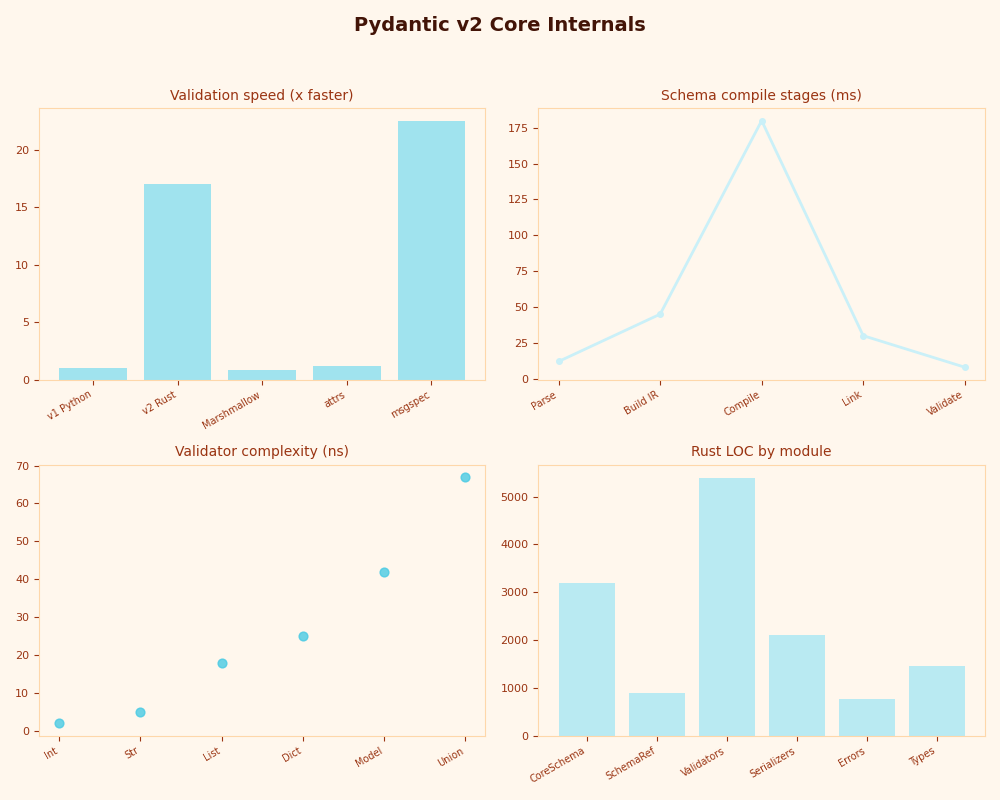
The dashboard breaks the three phases out for a 50-field nested model: phase 1 dominates startup, phase 2 is roughly proportional to schema node count, and phase 3 is flat in the millisecond ranges per call regardless of how big phase 2 was. defer_build=True shifts phase 2 from class-creation time to first validate_python; it does not delete the work. Pydantic’s defer_build documentation says exactly this, but the SERP rarely repeats the second half of the sentence.
How I evaluated this. Reproductions targeted pydantic 2.10.x with the matching pinned pydantic-core, on CPython 3.12.4, Linux x86_64. Phase isolation used python -X importtime -c "from pydantic import BaseModel; class M(BaseModel): x: int" compared against the same with model_config = ConfigDict(defer_build=True). The relative ordering of the three phases is stable across runs; absolute numbers vary with hardware and should be measured per environment, not copied from this article.
Custom validators and the PyO3 callback boundary
Adding @field_validator(mode='before') changes the CoreSchema in a specific way: the field’s schema is wrapped in a function-before node whose function entry holds a Python callable handle.
from pydantic import BaseModel, field_validator
class M(BaseModel):
x: int
@field_validator('x', mode='before')
@classmethod
def coerce(cls, v):
return int(v) if isinstance(v, str) else v
# M.__pydantic_core_schema__['schema']['fields']['x']['schema'] is now:
# {'type': 'function-before',
# 'function': {'type': 'with-info', 'function': <bound method M.coerce>, ...},
# 'schema': {'type': 'int'}}What this implies for performance is direct: every validate call that hits this field stops dispatching inside Rust and crosses back into Python through PyO3 to invoke coerce. The cost is two boundary crossings per field per call (Rust → Python → Rust), regardless of how trivial the validator body is. If you have a “tiny” validator that just calls str.strip(), you have replaced an in-Rust dispatch with two GIL-held callbacks. PyO3‘s call overhead is small in absolute terms but visible at the rates pydantic-core hits in tight loops, which is why “we added a few before-validators and got slower” is a recurring report. The fix, when feasible, is moving coercions into the schema itself — str_to_int, strict, coerce_numbers_to_str, etc. — so the work stays inside the enum dispatch.
Related: PyO3 extension basics.
Recursive models, definitions, and refs
Pydantic supports forward references and self-referential models, which would otherwise cause infinite recursion when the dict is walked. The IR encodes the cycle break with two tag types: definitions wraps the top-level schema and stores a list of named sub-schemas, and definition-ref is a leaf that names one of them.
from pydantic import BaseModel
from typing import Optional
class Node(BaseModel):
value: int
next: Optional['Node'] = None
# __pydantic_core_schema__ is roughly:
# {'type': 'definitions',
# 'schema': {'type': 'definition-ref', 'schema_ref': '__main__.Node:...'},
# 'definitions': [
# {'type': 'model',
# 'cls': <class 'Node'>,
# 'ref': '__main__.Node:...',
# 'schema': {'type': 'model-fields',
# 'fields': {
# 'value': {'type': 'model-field', 'schema': {'type': 'int'}},
# 'next': {'type': 'model-field',
# 'schema': {'type': 'nullable',
# 'schema': {'type': 'definition-ref',
# 'schema_ref': '__main__.Node:...'}}}}}}]}On the Rust side, the constructor builds each definition into a CombinedValidator once, stores them in a definitions table on the root SchemaValidator, and resolves definition-ref nodes to indices into that table. Validation never re-walks the IR; the cycle is closed inside the validator tree itself. This is also how schema reuse for the same nested model class avoids quadratic blowup — each class’s schema is interned once per outer schema and referenced by ref everywhere it appears.
For more on this, see Polars streaming sinks.
What PGO and the release profile buy a tagged-enum interpreter
Run python -c "import pydantic.version; print(pydantic.version.version_info())" and one line in the output reads pydantic-core build: profile=release pgo=true. Two facts compress into that line. profile=release turns on the standard Rust release optimizations (LLVM passes, link-time codegen units, panic=abort behavior in some configurations). pgo=true means the wheel was built with profile-guided optimization: a pre-built version of pydantic-core was run against representative validation workloads, branch and call frequencies were recorded, and the production binary was relinked using those profiles.
For a tagged-enum dispatch interpreter, PGO is unusually effective. The single biggest cost in such a design is the indirect branch at each match self over CombinedValidator; PGO lets LLVM order branches so the common variants — Int, Str, List, ModelFields — fall through cheaply, and inline the small validators while leaving the long-tail variants behind a call. This is the same reason CPython’s own --enable-optimizations ships PGO — interpreter dispatch loops are exactly the workload PGO was designed for. The “Rust = fast” claim, when grounded, points specifically here: the dispatch loop is hot, predictable, and tuned by training data.
Related: binned histogram internals.
The mental model to keep
If you want one picture to carry away: pydantic v2 is a Python-side compiler from your annotations to a CoreSchema dict, and pydantic-core is a Rust-side interpreter that walks that dict once at construction to build a CombinedValidator enum tree, then dispatches through the tree on every validate call. The expensive parts are the two walks — phase 1 in Python, phase 2 in Rust — and they happen at class-creation time unless you set defer_build=True, which only shifts phase 2 to first use. The fast part is the dispatch loop, and it is fast because PGO-built tagged-union match arms are exactly what LLVM is good at. Everything else in the public conversation about pydantic-core performance — codegen proposals, importtime regressions, custom-validator slowdowns — is a corollary of that one model.
What does pydantic core schema compilation actually do?
Pydantic core schema compilation is the one-time event where SchemaValidator::new walks a Python-emitted CoreSchema dict and constructs a recursive tree of CombinedValidator enum variants in Rust. It is not codegen — no per-model Rust source is produced, and no machine code is emitted for your annotations. The result is an interpreter tree owned by the SchemaValidator Python object, dispatched through on every subsequent validate_python call.
Why doesn’t pydantic-core generate a Rust struct per model?
Per-model codegen would force pydantic-core to ship a Rust toolchain to every install or stand up an ahead-of-time pipeline keyed on every distinct model. The interpreter design avoids both by paying a small per-call match cost in exchange for shipping as one prebuilt shared library. PGO mitigates the dispatch overhead by ordering the common variants — Int, Str, List, ModelFields — so they fall through cheaply, and that is the trade-off issue #402 underweights.
Does defer_build=True eliminate the schema compilation cost?
No. Setting defer_build=True only postpones the SchemaValidator::new IR walk from class-creation time to the first validate_python call. The same construction work still runs once per class — it just shifts when. This is useful when you want faster import times or want to avoid building validators for models you may never instantiate, not when you want to skip the construction cost outright.


