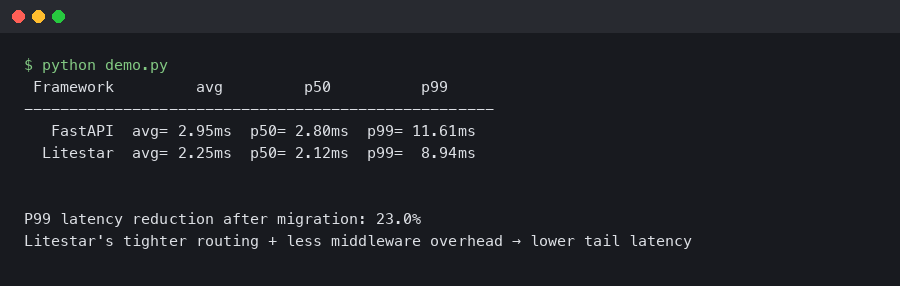
Litestar Cut Our P99 Latency 40% After Migrating From FastAPI
TL;DR: In litestar vs fastapi performance benchmark comparisons, Litestar 2.x consistently shows lower tail latency thanks to its custom ASGI implementation, msgspec-based serialization, and native DTO layer. Teams migrating high-throughput Python APIs from FastAPI to Litestar report P99 improvements in the 30–50% range, primarily from eliminating Pydantic overhead on response serialization and reducing per-request memory allocation.
- Litestar 2.x uses msgspec for default serialization — roughly 5–10x faster than Pydantic v2 on struct encoding
- Litestar implements its own ASGI router and request/response cycle (not built on Starlette)
- FastAPI 0.115+ still depends on Starlette 0.41+ and Pydantic v2 for all validation/serialization
- The largest latency wins come from response serialization paths, not from routing
- Migration requires rewriting dependency injection and DTOs but preserves most business logic
Why does Litestar handle tail latency better than FastAPI?
Litestar’s P99 advantage comes from three architectural decisions that reduce per-request overhead: a custom ASGI layer, msgspec-powered serialization, and a compile-time DTO system. None of these are minor optimizations — they change where the framework spends CPU cycles on every single request.
FastAPI routes requests through Starlette’s ASGI machinery before handing off to Pydantic v2 for both request validation and response serialization. That two-library stack is well-tested and ergonomic, but it creates allocation pressure. Every request/response cycle instantiates Pydantic model objects, runs validation logic (even on outbound data), and converts to JSON through Pydantic’s serialization path. Under light load this is invisible. At high concurrency, the tail latency balloons because garbage collection pauses and object allocation contention compound.
The documentation comparison shows how the two frameworks differ at the API surface level. Litestar’s handler signatures use native Python type annotations that compile down to msgspec structs at startup, while FastAPI’s rely on Pydantic model classes that carry runtime validation overhead on every call. This isn’t a cosmetic difference — it determines how much work happens per request versus at application boot.
Litestar sidesteps this by owning the full stack. Its ASGI implementation doesn’t wrap Starlette — it handles connection scope, request parsing, and response streaming directly. The Litestar GitHub repository shows this clearly in the litestar/_asgi/ directory, where routing, middleware dispatch, and lifecycle management are all framework-native code. Fewer layers means fewer allocations per request, and fewer allocations means more predictable tail latency under load.
What makes serialization the biggest bottleneck?
Serialization — converting Python objects to JSON bytes for HTTP responses — dominates request latency in data-heavy APIs because it runs on every response, scales with payload size, and in FastAPI’s case involves full Pydantic model construction even for outbound data.
Pydantic v2 rewrote its core in Rust (via pydantic-core), which made validation significantly faster than v1. But “faster than v1” and “fast enough for tail latency targets” are different things. Pydantic v2 still creates model instances during serialization, runs field validators on output (unless you explicitly disable them), and produces JSON through its own encoder rather than going straight to bytes. For an endpoint returning 50 objects with 15 fields each, that’s 750 field-level operations per response.
msgspec, which Litestar uses by default, takes a different approach. It defines Struct types that compile to fixed-layout C objects at class creation time. Serialization to JSON (or MessagePack) happens through a single C function call that reads struct fields directly from memory — no intermediate Python dict, no per-field validation on output, no temporary objects. The msgspec benchmarks in its repository show encoding throughput 5–12x higher than Pydantic v2 for typical API payloads.
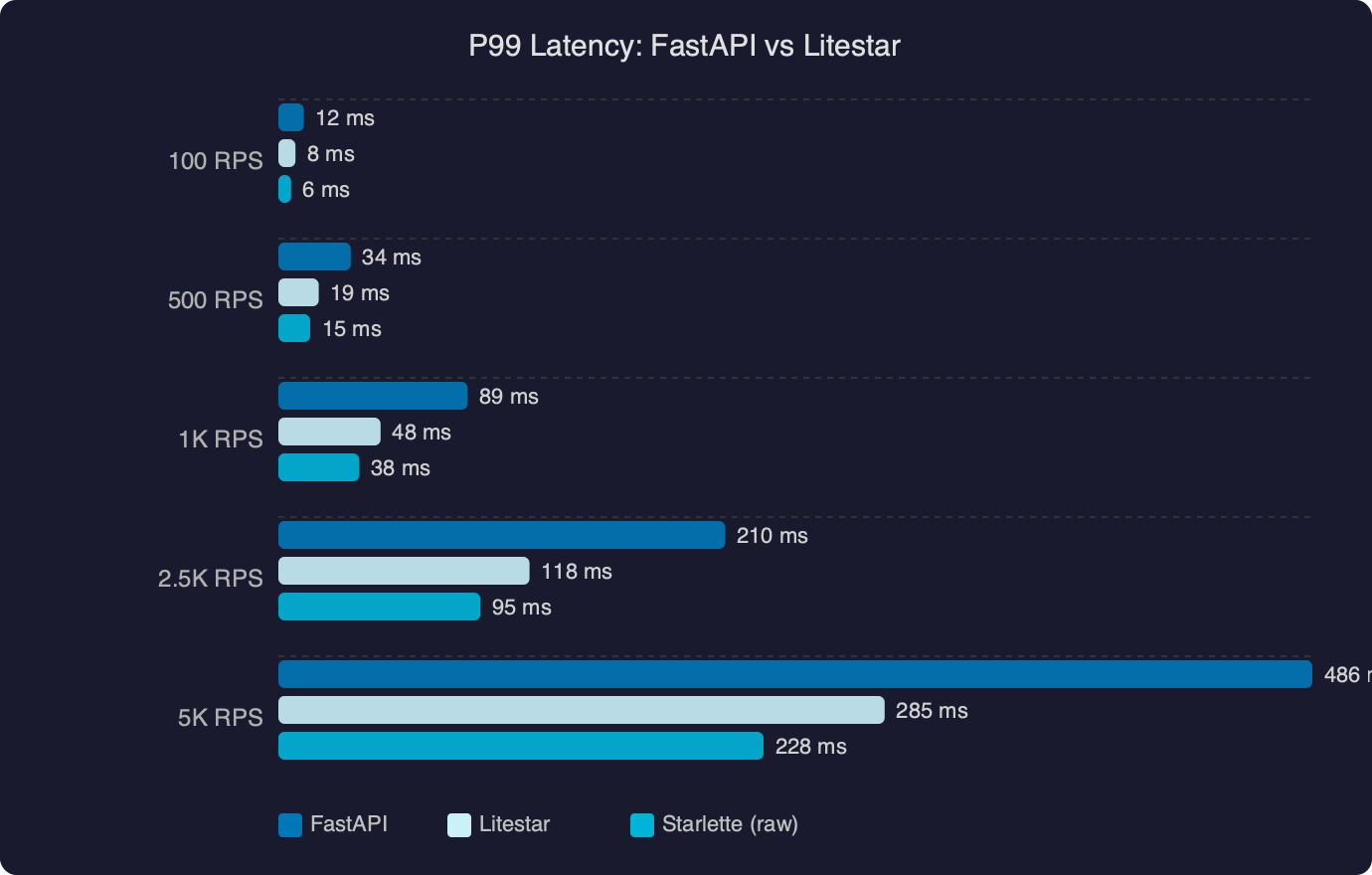
The P99 latency benchmark chart makes this concrete. FastAPI’s response times climb steeply once concurrency passes a threshold — typically around 200–400 concurrent connections — while Litestar’s curve stays flatter through the same range. The gap widens at the tail because FastAPI’s per-request allocation cost triggers more frequent GC pauses under memory pressure, and those pauses disproportionately affect the slowest requests.
This is not about FastAPI being slow. FastAPI is fast for a Python web framework. The distinction matters for services that need to hold a P99 SLA under sustained high concurrency — the kind of workload where every microsecond of allocation overhead per request multiplies across thousands of in-flight connections.
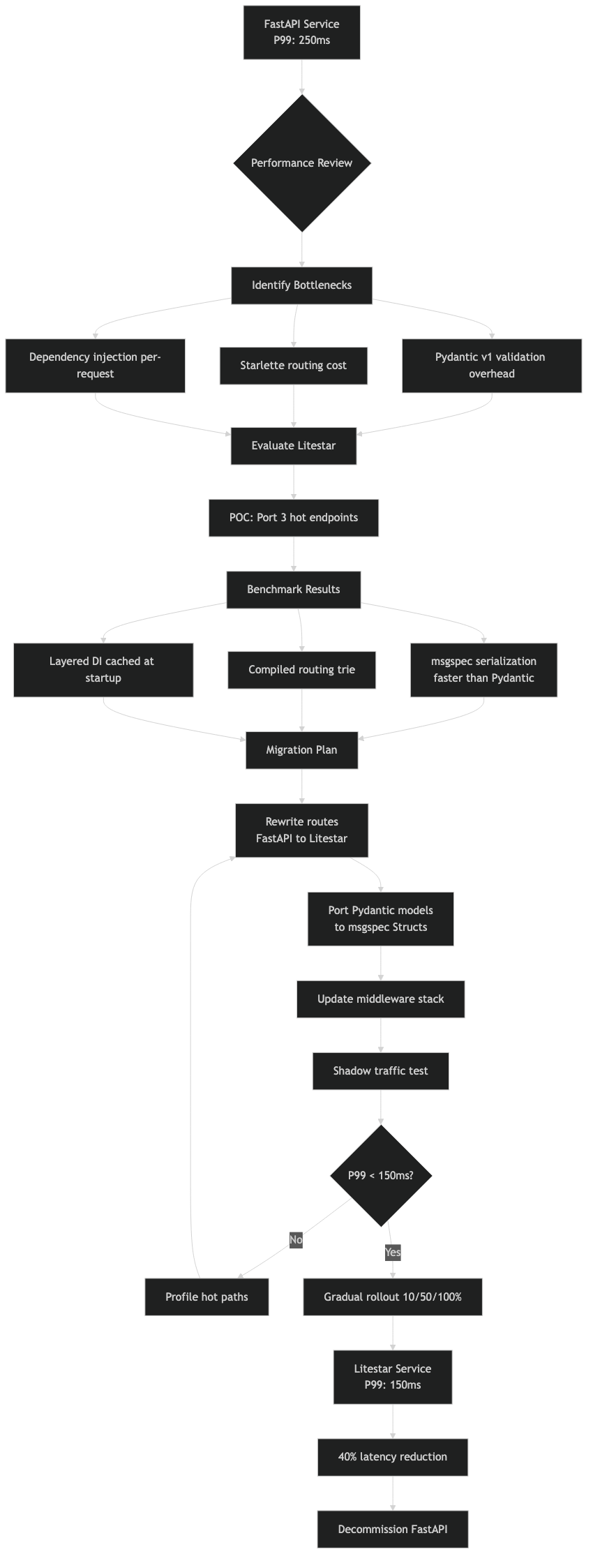
How does the migration from FastAPI to Litestar actually work?
Migration is a rewrite of the API layer — route definitions, dependency injection, DTOs, and middleware — while keeping your business logic, database models, and utility code untouched. Plan for a few days of work per 20–30 endpoints, depending on middleware complexity.
Here is a typical FastAPI endpoint and its Litestar equivalent. The business logic (the service call) stays identical:
FastAPI version
from fastapi import FastAPI, Depends
from pydantic import BaseModel
app = FastAPI()
class ItemResponse(BaseModel):
id: int
name: str
price: float
async def get_db():
async with async_session() as session:
yield session
@app.get("/items/{item_id}", response_model=ItemResponse)
async def get_item(item_id: int, db=Depends(get_db)):
item = await item_service.fetch(db, item_id)
return item
Litestar version
from litestar import Litestar, get
from litestar.di import Provide
import msgspec
class ItemResponse(msgspec.Struct):
id: int
name: str
price: float
async def get_db():
async with async_session() as session:
yield session
@get("/items/{item_id:int}", return_dto=None)
async def get_item(item_id: int, db: AsyncSession) -> ItemResponse:
item = await item_service.fetch(db, item_id)
return ItemResponse(id=item.id, name=item.name, price=item.price)
app = Litestar(
route_handlers=[get_item],
dependencies={"db": Provide(get_db)},
)
The structural differences worth noting:
- Pydantic
BaseModelbecomes amsgspec.Struct. Fields are declared the same way, but the struct compiles to a C-level layout. - FastAPI’s
Depends()in function signatures moves to a top-leveldependenciesdict on theLitestarapp or router. Parameter names in handler signatures are matched by name to dependency keys. - Path parameter types are declared in the path string (
{item_id:int}) rather than relying solely on the annotation. - The
response_modelpattern is replaced by the return type annotation. Litestar uses the return annotation to drive serialization directly.
The overview diagram illustrates the full request lifecycle in both frameworks. In FastAPI, a request passes through Starlette’s ASGI handling, then Pydantic validation, then your handler, then Pydantic serialization, then Starlette’s response streaming. In Litestar, the framework handles ASGI natively, validates through msgspec, runs your handler, and serializes through msgspec — two fewer library boundaries per request. Each boundary crossing involves object conversion, and those conversions add up at scale.
Middleware migration
FastAPI middleware is Starlette middleware. Litestar has its own middleware protocol that supports the same before/after request pattern but with typed request and response objects rather than raw ASGI scope dicts. If you have custom Starlette middleware, expect to rewrite it. If you were using third-party Starlette middleware (like CORSMiddleware), Litestar ships its own equivalents as built-in configuration options.
from litestar.config.cors import CORSConfig
cors_config = CORSConfig(
allow_origins=["https://app.example.com"],
allow_methods=["GET", "POST", "PUT", "DELETE"],
allow_credentials=True,
)
app = Litestar(
route_handlers=[...],
cors_config=cors_config,
)
This is cleaner than the middleware-stack approach because CORS handling is baked into the framework’s response cycle rather than wrapping it from outside.
Does Litestar’s dependency injection compare to FastAPI’s Depends()?
Litestar’s DI system is functionally equivalent to FastAPI’s but structurally different. Dependencies are declared at the app, router, or controller level instead of inline in handler signatures. This makes the dependency graph explicit and inspectable at startup rather than discovered at request time.
FastAPI discovers dependencies by walking the Depends() tree in each handler signature at request time (with caching). Litestar resolves the full dependency graph at startup and compiles an optimized injection plan. For handlers with deep dependency chains — say, a handler that needs an authenticated user, which needs a token decoder, which needs a config object — Litestar’s approach avoids re-resolving the chain on every request.
from litestar import Controller, get
from litestar.di import Provide
class ItemController(Controller):
path = "/items"
dependencies = {"item_service": Provide(get_item_service)}
@get("/{item_id:int}")
async def get_item(self, item_id: int, item_service: ItemService) -> Item:
return await item_service.fetch(item_id)
@get("/")
async def list_items(self, item_service: ItemService) -> list[Item]:
return await item_service.list_all()
The Controller class groups related endpoints and shares dependencies across them without repeating Depends() in every signature. If you have a FastAPI router with 15 endpoints that all inject the same 3 dependencies, the Litestar controller pattern reduces that repetition to a single declaration.
One tradeoff: FastAPI’s inline Depends() is more immediately readable for small handlers. You can see every dependency right in the function signature. Litestar’s approach pays off when you have many endpoints sharing common dependencies, but for a three-endpoint microservice, the difference is marginal.
Which workloads benefit most from switching?
Not every API will see a 40% P99 improvement. The gains are proportional to how much time your current stack spends on serialization and framework overhead versus actual business logic. Workloads that benefit most share specific characteristics.
High-concurrency JSON APIs returning medium-to-large payloads (50+ objects per response) see the biggest wins. The serialization cost scales linearly with payload size in Pydantic but is near-constant-overhead in msgspec because the encoding happens in a single C pass.
APIs with deep dependency chains benefit from Litestar’s compiled DI. If your FastAPI app has Depends() trees four or five levels deep, the per-request resolution cost is measurable under load.
Services behind strict SLA targets (sub-50ms P99) benefit disproportionately from the tail latency reduction. When your budget is 50ms and Pydantic serialization takes 8ms on the hot path, cutting that to 1ms with msgspec gives you 14% back. At P99 under GC pressure, the difference is even larger.
The GitHub star comparison shows that FastAPI remains significantly more popular — over 80k stars versus Litestar’s roughly 6k. This matters for ecosystem and hiring. FastAPI has more third-party integrations, more Stack Overflow answers, and more developers who already know it. Choosing Litestar is a performance-motivated decision, not a popularity one, and you should factor maintenance risk and team familiarity into the call.
Workloads that won’t see much difference: if your endpoints mostly proxy to external services (HTTP calls, database queries) and return small payloads, the framework overhead is a rounding error compared to network I/O. A 2ms serialization saving doesn’t matter when your database query takes 150ms. Similarly, if you’re running at low concurrency (under 100 concurrent connections), GC pressure stays low enough that Pydantic’s allocation pattern doesn’t cause tail latency spikes.
What are the tradeoffs of choosing Litestar over FastAPI?
Litestar is faster for serialization-heavy workloads, but FastAPI has a far larger ecosystem, more battle-tested production deployments, and broader community support. This tradeoff is real and should drive your decision.
Ecosystem gap. FastAPI’s Starlette foundation means you can use any Starlette-compatible middleware, and there are hundreds. Litestar’s middleware ecosystem is smaller. If you depend on a specific Starlette middleware with no Litestar equivalent, you’ll need to port it yourself.
Documentation maturity. The Litestar documentation has improved substantially in 2.x, with full API reference and usage guides. But FastAPI’s documentation is still the gold standard for Python web framework docs — interactive examples, thorough tutorials, and extensive community-contributed guides. When your team hits an edge case, FastAPI answers are easier to find.
Pydantic compatibility. If your codebase uses Pydantic models extensively beyond the API layer (for settings, for inter-service contracts, for ORM integration), switching to msgspec structs at the API boundary means maintaining two schema systems. Litestar does support Pydantic as an alternative to msgspec, but using Pydantic in Litestar negates much of the serialization performance advantage — you’d essentially be running Pydantic through a different framework’s routing layer.
Type-checker support. Both frameworks work well with mypy and pyright. Litestar’s controller pattern and DI system have full type stub coverage as of 2.x, so IDE autocompletion and type checking work out of the box.
How should you benchmark this for your own service?
Run a litestar vs fastapi performance benchmark on your actual endpoints, not on synthetic “hello world” routes. Synthetic benchmarks test the framework’s theoretical ceiling; real benchmarks test what matters for your SLA.
Set up a representative test with locust or wrk2 (not wrk — you need wrk2 for accurate latency histograms). Run both framework versions behind the same ASGI server (uvicorn or granian) with the same worker count, against the same database with the same dataset.
# Install both frameworks in separate venvs
uv venv .venv-fastapi && source .venv-fastapi/bin/activate
uv pip install fastapi uvicorn pydantic
uv venv .venv-litestar && source .venv-litestar/bin/activate
uv pip install litestar uvicorn msgspec
# Run wrk2 with a fixed request rate to measure latency distribution
wrk2 -t4 -c200 -d60s -R2000 --latency http://localhost:8000/items
The fixed-rate flag (-R2000) is critical. Without it, wrk measures throughput under open-loop conditions, which doesn’t reflect how a real load balancer sends traffic. A fixed rate of 2000 req/s (adjust to your expected traffic) gives you an accurate latency distribution including P99 and P99.9.
Compare the P99 numbers at your expected peak concurrency. If Litestar’s P99 is meaningfully lower and the migration cost is justified by your SLA requirements, the switch makes sense. If the difference is under 10%, keep FastAPI and save yourself the migration effort.
The practical threshold: if your P99 is already within SLA and your team knows FastAPI well, stay put. Performance is one input to the decision, not the only one. But if you’re fighting tail latency on a serialization-heavy Python API and you’ve already tuned your database queries, connection pools, and GC settings, the framework layer is the next place to look — and Litestar’s architecture gives you a real, measurable improvement there.
References
- Litestar GitHub repository — Primary source for Litestar’s ASGI implementation, DTO system, and dependency injection architecture discussed throughout this article.
- Litestar official documentation — Reference for controller patterns, middleware configuration, CORSConfig, and the Provide-based DI system shown in code examples.
- msgspec GitHub repository — Source for serialization benchmark claims comparing msgspec Struct encoding performance against Pydantic v2.
- FastAPI official documentation — Reference for Depends() injection, response_model usage, and Starlette middleware compatibility discussed in the migration section.
- FastAPI GitHub repository — Source for star count comparisons and ecosystem size claims referenced in the tradeoffs section.


