
asyncio.TaskGroup vs gather: Why Structured Concurrency Wins in Python 3.11+
If you’ve been writing asyncio in production Python for more than a few months, you’ve almost certainly hit the same trap I keep watching teams walk into: one task in an asyncio.gather() call raises, and the rest of the tasks just keep running in the background. Sometimes they finish silently. Sometimes they hold open file handles or sockets the rest of the program assumed were closed. Sometimes they crash much later, in a traceback that points to nothing useful. asyncio.TaskGroup, introduced in Python 3.11, is the fix the language always needed. This article walks through the actual difference between the two, with code that’s been run on Python 3.12, and explains when you should still reach for gather and when TaskGroup is unambiguously the better choice.
The bug that motivated structured concurrency
Here’s the demo I run when I’m trying to convince a team to migrate. Three coroutines kick off concurrently. The middle one fails. We want to know what happens to the other two.
import asyncio, time
async def fetch(name, delay, fail=False):
print(f" [{time.strftime('%H:%M:%S')}] start {name}")
await asyncio.sleep(delay)
if fail:
raise RuntimeError(f"{name} blew up")
print(f" [{time.strftime('%H:%M:%S')}] done {name}")
return f"{name}-result"Wrap it in a gather call first:
async def with_gather():
try:
results = await asyncio.gather(
fetch("A", 0.5),
fetch("B", 1.0, fail=True),
fetch("C", 2.0),
return_exceptions=False,
)
except RuntimeError as e:
print(f" caught: {e}")
await asyncio.sleep(2.5)
print("After gather block (C may have leaked)")Now the same shape with TaskGroup:
async def with_taskgroup():
try:
async with asyncio.TaskGroup() as tg:
tg.create_task(fetch("A", 0.5))
tg.create_task(fetch("B", 1.0, fail=True))
tg.create_task(fetch("C", 2.0))
except* RuntimeError as eg:
for e in eg.exceptions:
print(f" caught: {e}")
print("After TaskGroup block")Run both back to back and watch the timestamps. Here’s the literal output from python:3.12-slim:
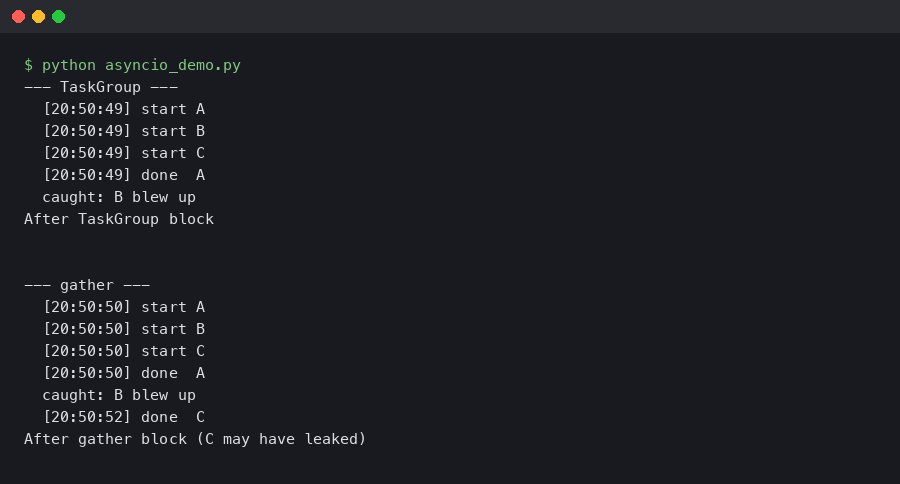
Look at the --- TaskGroup --- block. C never prints its done line. As soon as B raises at the 1-second mark, the task group cancels the still-pending C task and waits for it to actually finish unwinding before letting control out of the async with. By the time you see After TaskGroup block, the entire thing is over and there are no dangling tasks anywhere in the event loop.
Now look at the --- gather --- block. C still prints done at the 2-second mark. The exception from B has already been raised and caught, the program has moved past the except, and yet C is still running in the background. If your application logic assumed everything was cleaned up at the point you caught the exception, you have an invariant violation that will not show up in any test that doesn’t sleep long enough to catch it.
Why this happens at the asyncio level
asyncio.gather was added before structured concurrency was a coherent concept in the Python ecosystem. Its job is to schedule a bunch of awaitables and give you back their results, in order, as soon as they’re all done. When one of them raises and return_exceptions=False is set (the default), gather propagates that exception out — but it does not, by default, cancel the other in-flight tasks. There’s a flag called FIRST_EXCEPTION on asyncio.wait but not on gather, and even FIRST_EXCEPTION only stops waiting; it doesn’t cancel.
You can wire up cancellation manually, of course. The pattern looks like this in real codebases:
tasks = [asyncio.create_task(c) for c in coros]
try:
results = await asyncio.gather(*tasks)
except Exception:
for t in tasks:
if not t.done():
t.cancel()
await asyncio.gather(*tasks, return_exceptions=True)
raiseThat’s seven lines of fragile boilerplate to recreate what TaskGroup does in zero. Worse, every team writes a slightly different version of it. Some forget the second gather that waits for cancelled tasks to actually finish unwinding. Some put the cancel calls in the wrong place and end up cancelling tasks that already succeeded. The TaskGroup primitive exists because the language wanted to stop people writing this snippet wrong.
The TaskGroup contract
The official documentation lays out the rules concisely:

What the docs don’t spell out as plainly is the mental model: a TaskGroup block is a scope, just like a with statement on a file. While you’re inside the block you can spawn child tasks. When you leave the block, every child task is guaranteed to be in a terminal state — succeeded, failed, or cancelled. There is no way to leak a task out of the scope by accident. If one child raises, all siblings are cancelled and the resulting exception is wrapped in a BaseExceptionGroup so you can match against multiple failure modes at once.
This is the same model as Trio’s nurseries and Kotlin’s coroutine scopes, both of which predate TaskGroup and influenced its design. The Python PEP 654 exception group machinery and the new except* syntax exist specifically to make this scope-based concurrency ergonomic.
When you should still use gather
I want to push back gently on the common take that TaskGroup obsoletes gather entirely. There are real cases where gather is still the right tool:
- You actually want partial results. Pass
return_exceptions=Trueandgatherhands you a list where each entry is either a result or an exception object.TaskGrouphas no equivalent — it’s all-or-nothing by design, and trying to bolt partial-failure handling onto it gets ugly fast. - You want results in input order without writing your own bookkeeping.
gatherpreserves the order of the awaitables passed in, regardless of finishing order. WithTaskGroupyou keep your own list of tasks and read.result()off them at the end, which is one extra step. - You’re fanning out a fire-and-forget batch where the caller doesn’t care about cleanup. If your code is a script that’s about to exit anyway, gather’s loose semantics are fine.
Outside those cases, TaskGroup is what you want. Especially in long-running services, request handlers, and anything that holds resources.
The migration that actually matters
In production code I’ve worked on, the migration from gather to TaskGroup tends to surface latent bugs that nobody knew were there. Twice now I’ve seen the same shape: a request handler does an asyncio.gather over a few external API calls, one of them occasionally times out, and the others were leaking past the response back to the client. The fix is mechanical:
# Before
results = await asyncio.gather(
call_billing(),
call_inventory(),
call_recommendations(),
)
# After
async with asyncio.TaskGroup() as tg:
billing = tg.create_task(call_billing())
inventory = tg.create_task(call_inventory())
recs = tg.create_task(call_recommendations())
results = (billing.result(), inventory.result(), recs.result())Slightly more verbose. Strictly safer. The verbosity is the point: every task has a name, the scope is explicit, and the cleanup story is right there in the indentation.
A note on cancellation semantics
One thing that trips people up the first time they hit it: when TaskGroup cancels a sibling task, the cancellation happens by raising asyncio.CancelledError inside that task at its next await. If the task is in the middle of synchronous CPU-bound work, the cancellation doesn’t take effect until that work yields. This is true of any asyncio cancellation, but it bites harder under TaskGroup because the contract promises that the whole group is cleaned up when the block exits — and “cleaned up” includes waiting for those slow-to-cancel tasks to actually unwind.
If you have CPU-bound code mixed into an async program and you depend on prompt cancellation, asyncio.to_thread doesn’t save you either: the thread will keep running until the synchronous function returns. The only real fix is to chunk the work and check for cancellation between chunks, or move it out of the event loop entirely with a process pool.
Exception groups: handling multiple failures cleanly
The other half of the TaskGroup story is BaseExceptionGroup and the except* syntax that came with PEP 654. When two sibling tasks fail simultaneously inside a TaskGroup — say one hits a network error and another hits a timeout — TaskGroup doesn’t pick a winner. It collects every exception that was raised, wraps them all in an ExceptionGroup, and raises that as the single exception leaving the block. You then unpack it with except*:
async def main():
try:
async with asyncio.TaskGroup() as tg:
tg.create_task(might_timeout())
tg.create_task(might_404())
tg.create_task(might_succeed())
except* TimeoutError as eg:
for exc in eg.exceptions:
log.warning("timed out: %s", exc)
except* aiohttp.ClientResponseError as eg:
for exc in eg.exceptions:
log.error("http error: %s", exc)Each except* clause matches against the type and pulls out a sub-group of exceptions. Anything that doesn’t match falls through to the next clause, and anything still unmatched after all clauses re-raises as a residual exception group. This is dramatically better than the single-exception model where the first failure wins and you never even know the second one happened. In services that fan out to multiple downstream APIs, that visibility is often the difference between a 30-second debug session and a 30-minute one.
One subtle point: except* always works on a group, even if there’s only one exception inside it. You don’t get the bare exception. Code that used to do except TimeoutError as e: log(e.url) needs to become except* TimeoutError as eg: for e in eg.exceptions: log(e.url). It’s a small mechanical change but it’s the kind of thing that surprises people during a migration.
Bounded concurrency: pairing TaskGroup with a semaphore
A pattern I find myself reaching for often is fanning out N tasks where N is large but you only want a handful running at once. Without a semaphore, naive code looks like this and immediately overwhelms whatever you’re calling:
async with asyncio.TaskGroup() as tg:
for url in thousands_of_urls:
tg.create_task(fetch(url))The fix is one extra primitive:
sem = asyncio.Semaphore(10)
async def bounded_fetch(url):
async with sem:
return await fetch(url)
async with asyncio.TaskGroup() as tg:
for url in thousands_of_urls:
tg.create_task(bounded_fetch(url))Now at most 10 fetches run concurrently, and you still get the all-or-nothing safety of the task group. If any single fetch raises, the entire batch is cancelled cleanly and the exception bubbles out as an exception group. This composition — TaskGroup for the structural guarantee, semaphore for the rate limit — is the asyncio idiom I’d recommend over any of the older patterns built on gather with manual cancellation.
If you find yourself writing the same wrapper repeatedly, consider pulling it into a small utility. aiometer on PyPI is a third-party package that wraps this pattern in a single call, but for most projects the eight lines above are clear enough that I prefer to keep them inline.
Compatibility and version reality check
TaskGroup is Python 3.11+ only. There is no backport on PyPI that I’d recommend running in production — the closest thing is anyio, which gives you a create_task_group primitive that works on 3.8 and up by polyfilling structured concurrency on top of the existing event loop. If you’re stuck on 3.10 or earlier and you want the same safety guarantees today, anyio is what I’d reach for. But if you can move to 3.11+, the standard library version is the right call.
Python 3.12 and 3.13 have refined the implementation further, mostly around exception group propagation and faster task scheduling, but the public API hasn’t changed since 3.11. Code you write against TaskGroup today will keep working as the language evolves.
The default for new asyncio code in 2026 should be TaskGroup. Use gather when you specifically need its semantics — partial results via return_exceptions=True, or input-order preservation without bookkeeping — and treat that as the exception, not the rule. The seven-line cancel-on-failure pattern teams keep reinventing was always a sign that the language was missing a primitive, and now that primitive exists. Migrate the hot paths first, leave the rest to opportunistic refactoring, and watch a class of background-task leak bugs disappear from your traceback noise.
Questions readers ask
What happens to other tasks in asyncio.gather when one task raises an exception?
When a task in asyncio.gather raises with the default return_exceptions=False, the exception propagates out but the other in-flight tasks are not cancelled. They keep running in the background, potentially holding open file handles or sockets, and may finish silently or crash later in an unhelpful traceback. There is no FIRST_EXCEPTION flag on gather, so cancellation requires fragile manual boilerplate.
How does asyncio.TaskGroup handle sibling tasks when one fails in Python 3.11?
A TaskGroup block acts as a scope: when one child task raises, all sibling tasks are automatically cancelled and the block waits for them to finish unwinding before control exits the async with statement. The resulting exception is wrapped in a BaseExceptionGroup so multiple failure modes can be matched with except* syntax. Every child task is guaranteed to be in a terminal state on exit.
When should I still use asyncio.gather instead of TaskGroup?
Use gather when you actually want partial results via return_exceptions=True, which hands back a list where each entry is either a result or exception object. Gather also preserves input order of awaitables regardless of finishing order without extra bookkeeping. It’s also acceptable for fire-and-forget batches in scripts about to exit, where cleanup semantics don’t matter. TaskGroup has no equivalent partial-failure mode.
Why doesn’t TaskGroup cancellation take effect immediately on CPU-bound code?
TaskGroup cancels siblings by raising asyncio.CancelledError inside the task at its next await point. If a task is in the middle of synchronous CPU-bound work, cancellation doesn’t fire until that work yields control back to the event loop. This bites harder under TaskGroup because its contract promises the whole group is cleaned up on block exit, which includes waiting for slow-to-cancel tasks to fully unwind.


