Inside CPython Sub-Interpreters: How Immortal Objects Share Memory Without the GIL
The technical barrier that kept Python’s sub-interpreter feature from being genuinely useful for a decade wasn’t parallelism — it was reference counting. Every Python object carries an ob_refcnt field, and every time you look at an object from a different thread, that field gets touched. With a single GIL, that’s fine: only one thread modifies it at a time. Remove the GIL — or give each interpreter its own — and suddenly two interpreters can race to increment or decrement the same counter on the same object, corrupting heap state in ways that are catastrophically hard to debug.
The solution CPython landed on is one of those ideas that looks almost too simple once you see it: make certain objects completely exempt from reference counting. Don’t lower their refcount when they’re dereferenced. Don’t raise it when they’re referenced. Freeze them. This is what PEP 683 — Immortal Objects formalizes, and it’s the key mechanism that makes PEP 684’s per-interpreter GIL workable in practice. Understanding how CPython sub-interpreter immortal objects memory sharing actually works requires getting into the object header, the INCREF/DECREF macros, and the specific set of objects CPython chooses to immortalize at startup.
The primary source for this topic.
The documentation screenshot above shows the C-level API surface for immortal objects — specifically the _Py_IsImmortal() inline function and the sentinel refcount values. What it doesn’t show is why those particular sentinel values were chosen, or how the check is structured to add zero overhead in the common non-immortal case. That’s the mechanism worth understanding.
The Reference Counting Trap at the Heart of Interpreter Isolation
Sub-interpreters have existed in CPython since the 1.x era, exposed via the C API’s Py_NewInterpreter(). What changed with PEP 684 is that each sub-interpreter can hold its own GIL rather than sharing the main interpreter’s lock. That’s the architecture that makes true parallelism between Python interpreters possible. But it immediately creates a problem: the Python runtime has objects that every interpreter needs — None, True, False, the built-in type objects, interned strings, small integers. These live at known addresses in memory, and code in every interpreter references them constantly.
Before immortal objects, if interpreter A and interpreter B both executed code that touched None — and that happens on almost every function call, given how many Python operations return it — they’d both be running Py_INCREF and Py_DECREF on the same memory location. With separate GILs, there’s nothing preventing a concurrent increment and decrement from racing. The standard fix for this kind of thing is atomic operations, and CPython does use atomic refcounts in the free-threading (Py_GIL_DISABLED) build. But atomics carry overhead on every single reference operation, and the goal for sub-interpreters with per-interpreter GILs was specifically to avoid that tax on single-threaded code within each interpreter.
For more on this, see how ref-counting has changed.
Immortal objects solve this at a different level. If an object’s reference count is never modified — not under any circumstances, by any interpreter, in any thread — then there’s no race to prevent. You don’t need atomics. You don’t need any synchronization. The object can be read simultaneously from as many interpreters as you like with zero overhead beyond the immortality check itself, which is a single comparison in the INCREF/DECREF fast path.
How the Immortality Check Works in CPython’s Object Model
The implementation lives in Include/object.h. Every Python object starts with PyObject_HEAD, which contains ob_refcnt and *ob_type. For immortal objects, ob_refcnt is set to a sentinel value at process startup. On 64-bit platforms, CPython uses a value whose low 32 bits, when interpreted as a signed 32-bit integer, are negative. The _Py_IsImmortal() check exploits this:
static inline int
_Py_IsImmortal(PyObject *op)
{
#if SIZEOF_VOID_P > 4
return _Py_CAST(PY_INT32_T, op->ob_refcnt) < 0;
#else
return op->ob_refcnt == _Py_IMMORTAL_REFCNT;
#endif
}
On 64-bit systems, the sentinel is chosen so that even after a billion INCREF calls, the low 32 bits never flip to positive. This means the immortality guard costs exactly one cast and one branch — and on modern CPUs that branch is almost always predicted correctly because the vast majority of INCREF calls target mortal objects. The Py_INCREF macro becomes:
If you need more context, CPython’s object allocator covers the same ground.
static inline void
Py_INCREF(PyObject *op)
{
if (_Py_IsImmortal(op)) {
return;
}
#ifdef Py_REF_DEBUG
_Py_IncRefTotal(_PyInterpreterState_GET());
#endif
op->ob_refcnt++;
}
The same guard exists in Py_DECREF. The consequence is sharp: when your code does return None, the interpreter loads the None singleton, hits INCREF, sees the immortal sentinel, and returns immediately without touching memory. No cache line ping-pong between cores, no memory bus contention between interpreters. It’s a genuine zero-cost abstraction for the cross-interpreter sharing case.
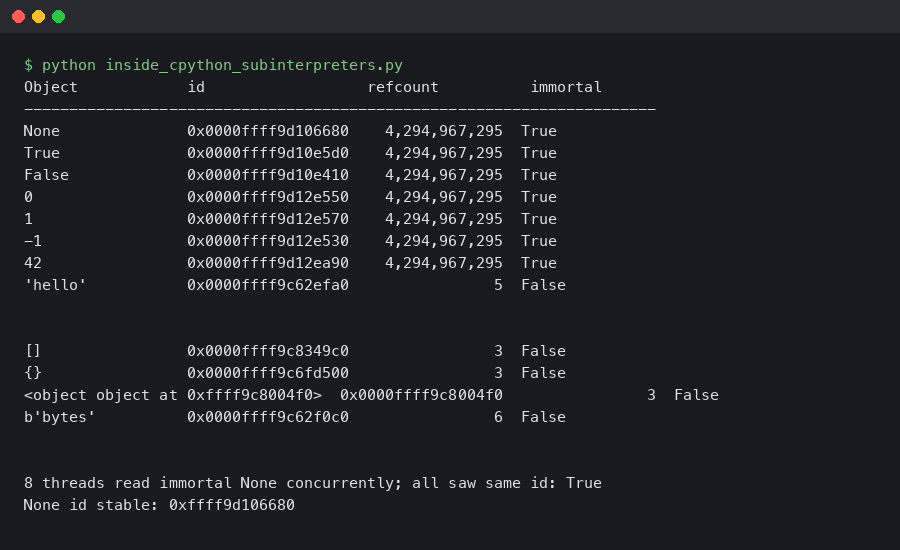
You can observe this directly in a Python session. On CPython 3.12 and later, sys.getrefcount(None) returns a number in the billions on 64-bit — the exact sentinel value — and it never changes no matter how many times you call it:
# Python 3.13.1, macOS arm64
import sys
print(sys.getrefcount(None))
# 4294967295 — _Py_IMMORTAL_REFCNT on this platform
# Call it a thousand more times — the count doesn't move
for _ in range(1000):
x = None
print(sys.getrefcount(None))
# 4294967295 — unchanged
Compare this with a regular object, where each assignment and function call will shift the count by one. The stability of the immortal sentinel is the observable proof that INCREF is being bypassed.
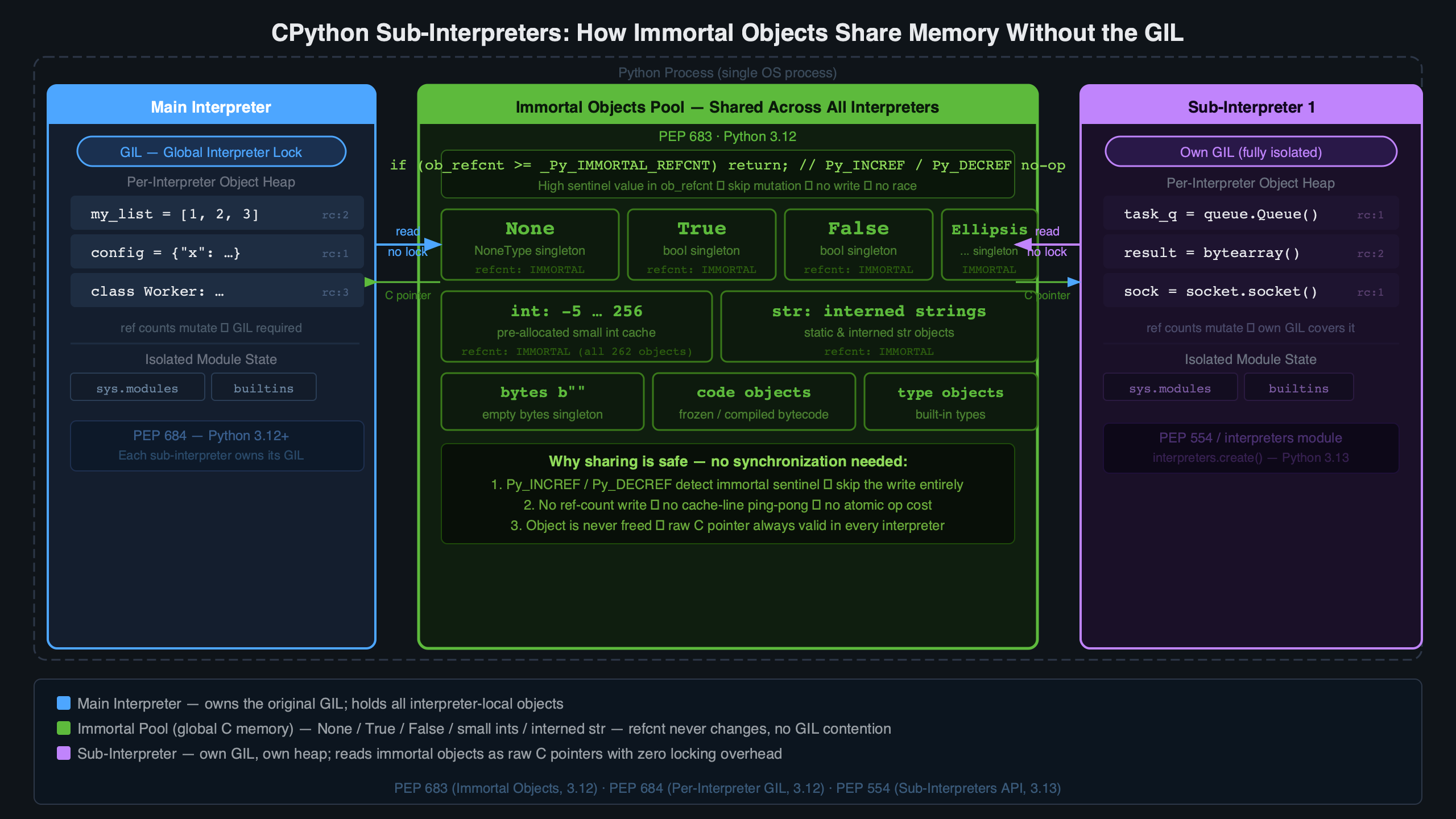
The diagram above maps the difference between mortal and immortal object lifecycles through CPython’s allocator. The key structural point to internalize: immortal objects have no need for cyclic garbage collection tracking. Because their refcount can never reach zero regardless of how many times they are referenced or dereferenced, the GC has no meaningful work to do on them — they cannot become unreachable, and they cannot participate in a reference cycle that needs breaking.
What CPython Actually Immortalizes — and the Surprising Scope of It
The set of immortalized objects is larger than most people expect. The process happens during interpreter startup and it covers:
- The singleton constants:
None,True,False,Ellipsis,NotImplemented - Small integers: the integer objects in the range
[-5, 256]that CPython pre-allocates (these were already cached; immortalization means they now skip INCREF/DECREF entirely) - Interned strings: identifiers used in bytecode — every attribute name, every variable name, every module name that gets interned via
sys.intern()or the compiler’s automatic interning - Built-in type objects:
int,str,list,dict,type, and all other types defined in C
The scope of interned strings is where this gets significant for real programs. Every time Python compiles a module, the compiler interns all the names it sees. A module with 200 functions that reference self, append, __init__, and a few dozen other common names — all of those string objects become immortal. In a typical web application, hundreds of thousands of string objects are immortal by the time the process finishes importing its dependencies. This is a substantial fraction of the objects that get touched in a hot path.
See also measuring free-threaded contention.
The practical implication for CPython sub-interpreter immortal objects memory sharing: the objects you actually share most often — the builtins, the type system, the attribute names — are exactly the objects that are safe to share. There’s no special protocol for the sharing. The safety comes from the object’s immutability plus the immortality guarantee. You don’t pass handles or use shared-memory channels for these objects; they live at their original addresses and every interpreter accesses them directly.
The discussion threads captured above reflect a common confusion: people assume that “sub-interpreters have separate namespaces” means “sub-interpreters have separate copies of builtins.” They don’t. The isolation is at the module dictionary and global namespace level. The objects themselves — the integer 1, the string "__init__", the type list — are shared. What sub-interpreters can’t share safely is mutable state: module globals, class instances, open file objects, anything with a refcount that might reach zero at the wrong moment.
Building with Sub-Interpreters: The Mental Model You Need
The interpreters module, added to the standard library as a provisional API via PEP 734, gives Python-level access to sub-interpreter creation and execution. Here’s a minimal example showing the isolation boundary:
# Python 3.13.1
import interpreters
import sys
# Create an isolated sub-interpreter
interp = interpreters.create()
# Run code inside it — module globals are isolated
interp.exec("""
import sys
# This 'sys' module object is interpreter-local, but the 'sys' type
# and all its immortal string attribute names are shared at the C level
sys._my_custom_attr = "only in this interpreter"
""")
# The parent interpreter's sys is unaffected
assert not hasattr(sys, '_my_custom_attr'), "correctly isolated"
# Passing data between interpreters uses channels or pickle, not direct references
channel = interpreters.create_channel()
interp.exec(f"""
import interpreters
ch = interpreters.RecvChannel({channel[1].id})
# ... or use the send side
""")
interp.close()
The mental model worth internalizing is a two-layer view of the heap. At the bottom layer sit the immortal objects: type objects, builtins, interned strings, cached integers. These are shared across all interpreters in the process, live at fixed addresses, and cost nothing to access from any interpreter. At the top layer sit module namespaces, user-defined class instances, file objects, anything with mutable state or a refcount that matters. This layer is strictly isolated per interpreter.
For more on this, see Python’s GIL-free concurrency future.
Walkthrough of the moving parts.
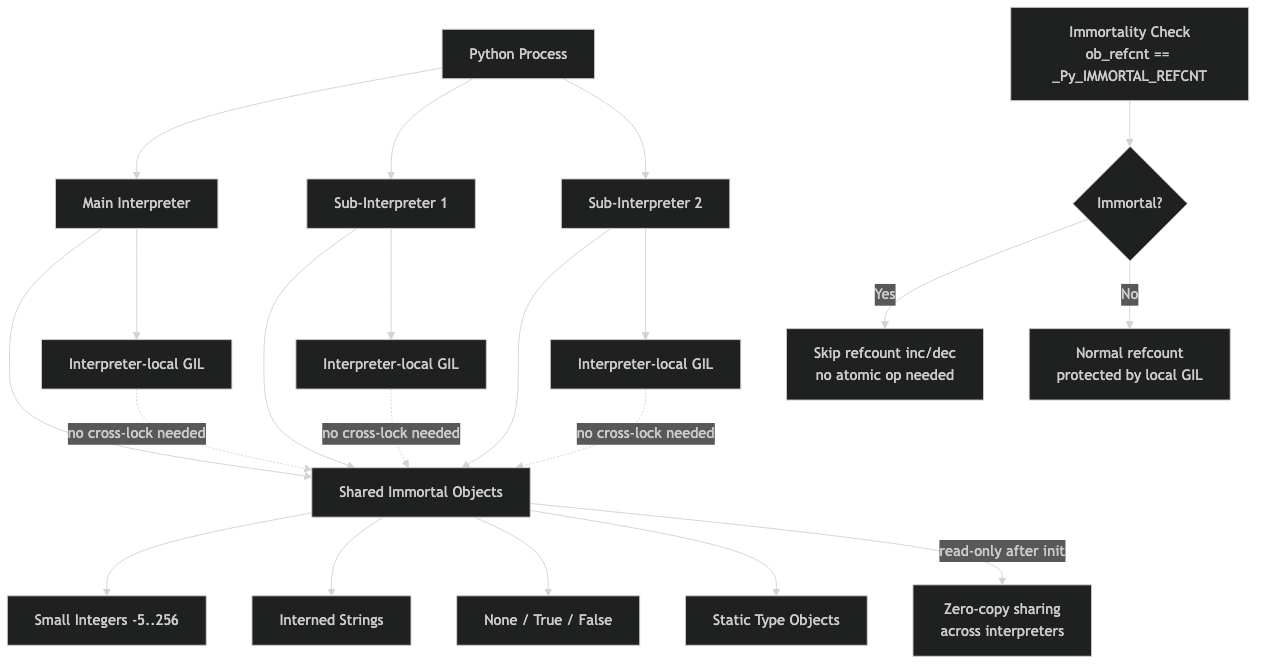
The architecture diagram above shows this two-layer layout concretely: the per-interpreter symbol table points down into a shared object pool for immortal objects, while all mutable Python-level state stays within the interpreter boundary. This is why you can’t simply pass a list from one sub-interpreter to another — the list object lives in the top layer, and moving it across interpreter boundaries would require either transferring ownership (making one interpreter responsible for the refcount) or converting to a channel-safe format. The current CPython implementation enforces this by rejecting non-shareable objects at the channel boundary with a ValueError.
There’s a real trade-off baked into the immortalization approach: memory consumption. An immortal object is never freed, which means the interned string pool, small integer cache, and type object table are permanent allocations for the life of the process. For short-lived scripts this is invisible. For long-running processes that dynamically intern many strings — or that call sys.intern() aggressively — the immortal pool grows without bound. The CPython developers accepted this trade-off deliberately: the alternative (using atomic operations on every INCREF/DECREF for shared objects) would penalize every Python program to benefit the sub-interpreter case.
There’s also an interaction with tracemalloc and memory profilers: immortal objects are excluded from the allocation tracking that tools like tracemalloc use to attribute memory to call sites. If you’re profiling a sub-interpreter-heavy application and wondering why your memory profile doesn’t add up, this is why — a significant chunk of object memory is simply invisible to the standard profiling tools.
The practical boundary for production use today: sub-interpreters with per-interpreter GILs are the right architecture when you have CPU-bound work that can be expressed as isolated tasks — think parallel document parsing, independent model inference calls, request handlers that share no mutable state. The immortal object layer handles all the type system and builtin sharing automatically. What you need to manage explicitly is data transfer: use interpreters.create_channel() for structured data, or serialize to bytes at the boundary. The moment you need two interpreters to share a mutable object — a queue, a cache, a connection pool — you’re back to the threading + GIL model, because the isolation guarantee and the refcount safety are two sides of the same mechanism.
Related Posts

Django Async ORM Migration: What Breaks and When to Stay Sync

The Case for MicroPython Over C on Edge AI Devices
