Data Engineering
Posts about Data Engineering

Taipy: Why I Finally Ditched Streamlit for Production Apps
Well, I have a confession to make. For the last five years, I’ve been utterly hooked on “script-to-web” tools.

LlamaCloud’s Multimodal RAG: Finally, No More Glue Code
Well, that’s not entirely accurate — I’ve actually been playing around with LlamaCloud for a while now. You know the drill.

Mojo in 2026: Is It Finally Time to Ditch Pure Python?
Actually, I still remember the noise when Mojo first dropped. It was mid-2023, and the promise was wild: Python syntax, C++ speed, and a magical.
Python’s Reference Counting Has Changed (And You Probably Missed It)
Well, that’s not entirely accurate — I actually spent most of last Tuesday staring at a flame graph that absolutely refused to make sense.

Distributed Training Finally Stopped Making Me Cry (Mostly)
I still remember the first time I tried to shard a 70B parameter model across a cluster of GPUs. It was 2 AM, I was three coffees deep, and the error logs.

Stop Rewriting Your Pandas Code for Spark. Seriously.
I looked at my terminal yesterday and saw the one error message that has haunted my entire career in data engineering.

NASA Just Paid to Fix NumPy’s Messy Parts. About Time.
I was staring at a flame graph at 11 p.m. last Tuesday, wondering why my seemingly simple data pipeline was eating RAM like Chrome with fifty tabs open.
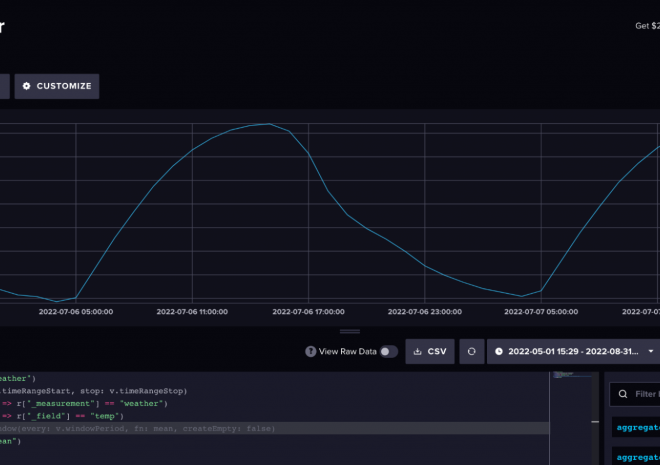
Stop Downsampling Your Data: The New Pandas Update is Actually Good
I have a confession to make. For the last five years, I’ve been lying to my stakeholders. Not big lies—just little white lies about data granularity.

Stop Renting Cloud Computers: Building a Data Stack on Localhost
I looked at my AWS bill last month and laughed. Not the happy kind of laugh. The kind that sounds a bit like a sob.

Mojo in 2025: A Python Dev’s Honest Look Under the Hood
I have a love-hate relationship with Python. We all do, right? It’s the glue holding the entire AI ecosystem together, yet every time I watch a profiler.